
编译原理 期末复习 运行环境
程序运行时的存储组织
过程与活动
与程序的执行密切相关的概念。
过程的定义
- 一个声明语句
- 把一个标识符(过程名)和一个语句(过程体)联系起来
过程的分类
- 过程:没有返回值的过程
- 函数:有返回值的过程
- 也可以把函数、一个完整的程序看作过程
过程引用:过程名出现在一个可执行语句中
参数
- 形参
- 实参
活动的定义
- 一个过程的每次执行
- 如果一个过程在执行中,则称它的这次活动是活着的。
过程与活动
- 过程是一个静态概念,活动是一个动态概念。
- 过程与活动之间可以是1:1或者1:m的关系。
- 递归过程,同一时刻可能有若干个活动是活着的(当然多线程就更有可能了)
- 每个活动都有自己独立的存储空间**/**数据空间。
活动的生存期
活动的生存期指的是过程体的执行中,第一步和最后一步之间的一系列步骤的执行时间
程序执行时,过程之间的控制流是连续的。
过程的每一次执行都是从过程体的起点开始,最后控制返回到直接跟随本次调用点的位置
过程P的一次活动的生存期,包括执行过程P所调用的过程的时间,以及这些过程所调用的过程的时间
如果a和b是过程的活动,那么它们的生存期要么是不重叠,要么是嵌套的。
对于递归过程:
- 如果一个过程,它的不同活动的生存期可以嵌套,则这个过程是递归的
- 直接递归、间接递归
程序运行空间的划分
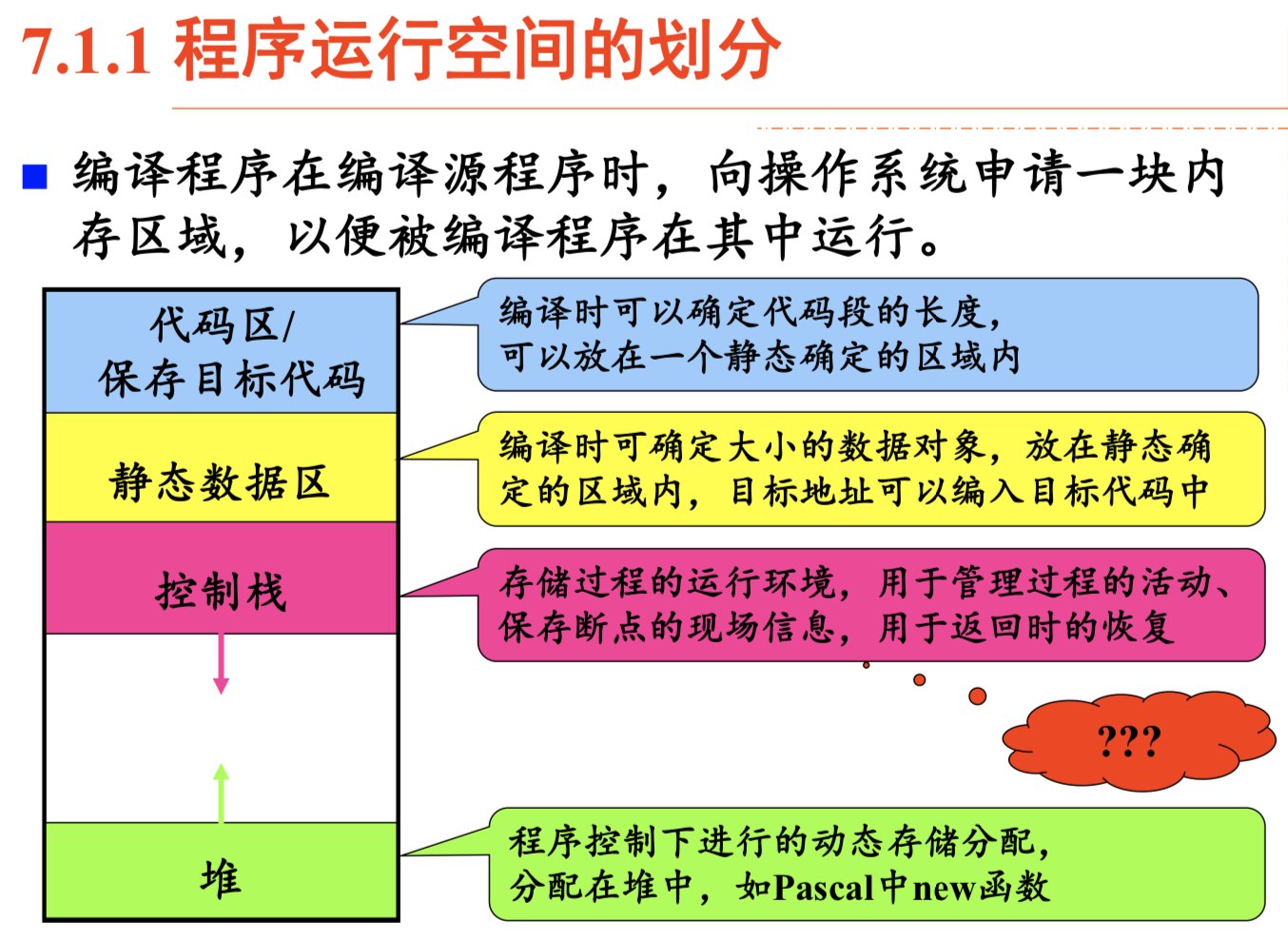
活动记录与控制栈
允许过程递归调用的语言(如Pascal、C等),过程块的活动空间不能静态分配。
-
有可能在递归过程的前一次活动结束之前又开始了一次新的活动
-
在某段时间内,一个递归过程的多次活动可能同时活着。
为保证程序的正确执行,需要为过程的每次活动分配不同的存储空间,通常采用栈式存储分配策略来实现
活动记录
一个连续的存储块
可以记录过程在一次执行中所需要的信息。
活动记录的内容与组织

控制站与活动记录
控制栈
- 程序运行空间中的存储区域
- 以栈的形式组织和管理
- 保存当前活着的活动的活动记录
控制栈记录活动的生存踪迹及活动的运行环境
同时,栈空间的分配和回收,就是活动记录的入栈和出栈
当一个过程被调用时,被调用过程的一次新的活动被激活,在栈顶为该活动创建一个新的活动记录来保存其环境信息;
当活动结束,控制从被调用过程返回时,释放该活动记录, 使调用过程的活动记录成为栈顶活动记录,即恢复调用过程的执行环境。
名字的作用域与名字绑定
把名字映射到存储单元的过程。
在静态作用域规则下,名字的存储空间被安排在其声明所在过程的活动记录中。
名字与存储单元的对应关系
- 不同的名字被绑定到不同的存储单元。
- 不同作用域的同名变量,分别被绑定到不同的存储单元。
- 即使在一个程序中每个名字只被声明一次,程序运行期间, 同一个名字也可能映射到不同的存储空间(如递归过程中声明的名字)
名字绑定
程序运行期间,名字的值有左右之分
- 左值指的是其存储空间的地址
- 右值指的是其存储空间的内容
- 赋值语句的执行仅改变名字的右值,不改变其左值
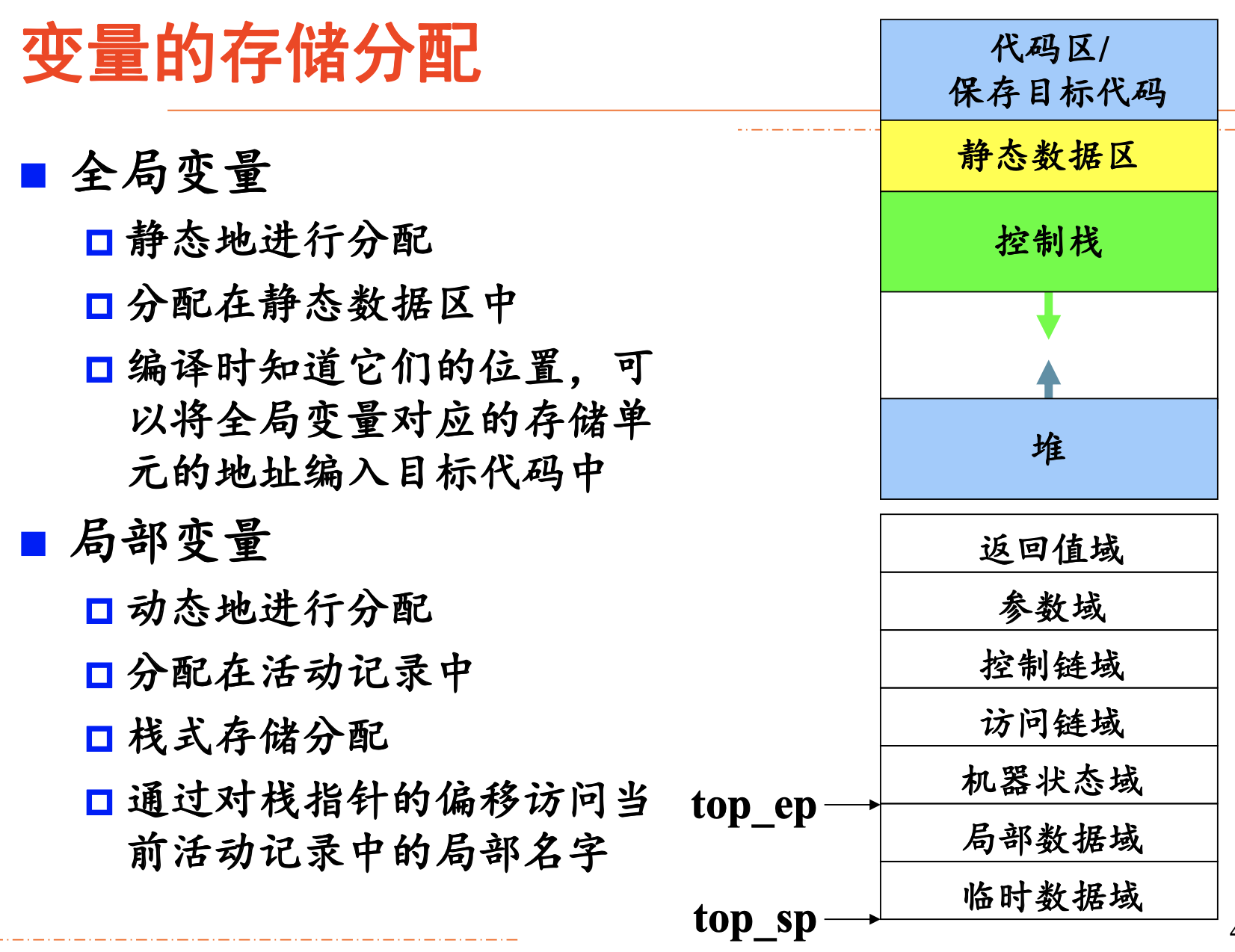
存储分配策略
运行时刻存储空间的划分
除目标代码外,其余三种数据空间采用的存储分配策略是不同的。
- 静态存储分配:编译时对所有数据对象分配存储空间。
- 栈式存储分配:运行时把存储空间组织成栈进行管理,数据对象分配在栈中。
- 堆式存储分配:运行时把存储空间组织成堆进行管理。
静态存储分配
条件:源程序中声明的各种数据对象所需存储空间的大小在编译时都可以确定
-
存储分配:编译时,为他们分配固定的存储空间
- 每个过程的活动记录的大小及位置
- 活动记录中每一个名字所占用存储空间的大小及位置
- 数据对象的地址可以生成在目标代码中
-
地址绑定:程序装入内存时进行
-
运行期间:名字的左值保持不变
- 过程每次被激活,同一名字都使用相同的存储空间
- 允许局部名字的值在活动结束后被保留下来
- 当控制再次进入时,局部名字的值即上次离开时的值
-
静态存储分配策略对源语言的限制
-
数据对象的大小和它们在内存中的位置必须在编译 时都能够确定。
-
不允许过程递归调用
因为使用静态存储分配,一个过程中声明的局部名字在该过程的所有活动中都结合到同一个地址
-
不能建立动态数据结构
因为没有在运行时进行存储分配的机制
-
静态存储分配策略的实现
- 编译程序处理声明语句时,每遇到一个变量名就创建一个符号表条目,填入相应的属性,包括名字、类型、存储地址等。
- 每个变量所需存储空间的大小由其类型确定,并且在编译时是已知的。
- 根据名字出现的先后顺序,连续分配空间
栈式存储分配
存储空间被组织成栈
- 活动开始时,与活动相应的活动记录入栈。 局部变量的存储空间分配在活动记录中,同一过程中声明的名字在不同的活动中被绑定到不同的存储空间。
- 活动结束时,活动记录出栈。 分配给局部名字的存储空间被释放。名字的值将丢失,不可再用。
调用序列和返回序列

调用序列:目标程序中实现控制从调用过程进入被调用过程的一段代码。
- 功能:实现活动记录的入栈和控制的转移
- 其中有调用过程和被调用过程各自需要完成的任务。如:
- 调用者:准备并传递实参,为被调用者创建访问非局部名字的环境等。
- 被调用者:保存调用点环境、初始化局部变量等。
返回序列:目标程序中实现控制从被调用过程返回到调用过程的一段代码。
- 功能:实现活动记录的出栈和控制的转移。
- 其中有调用过程和被调用过程各自需要完成的任务。
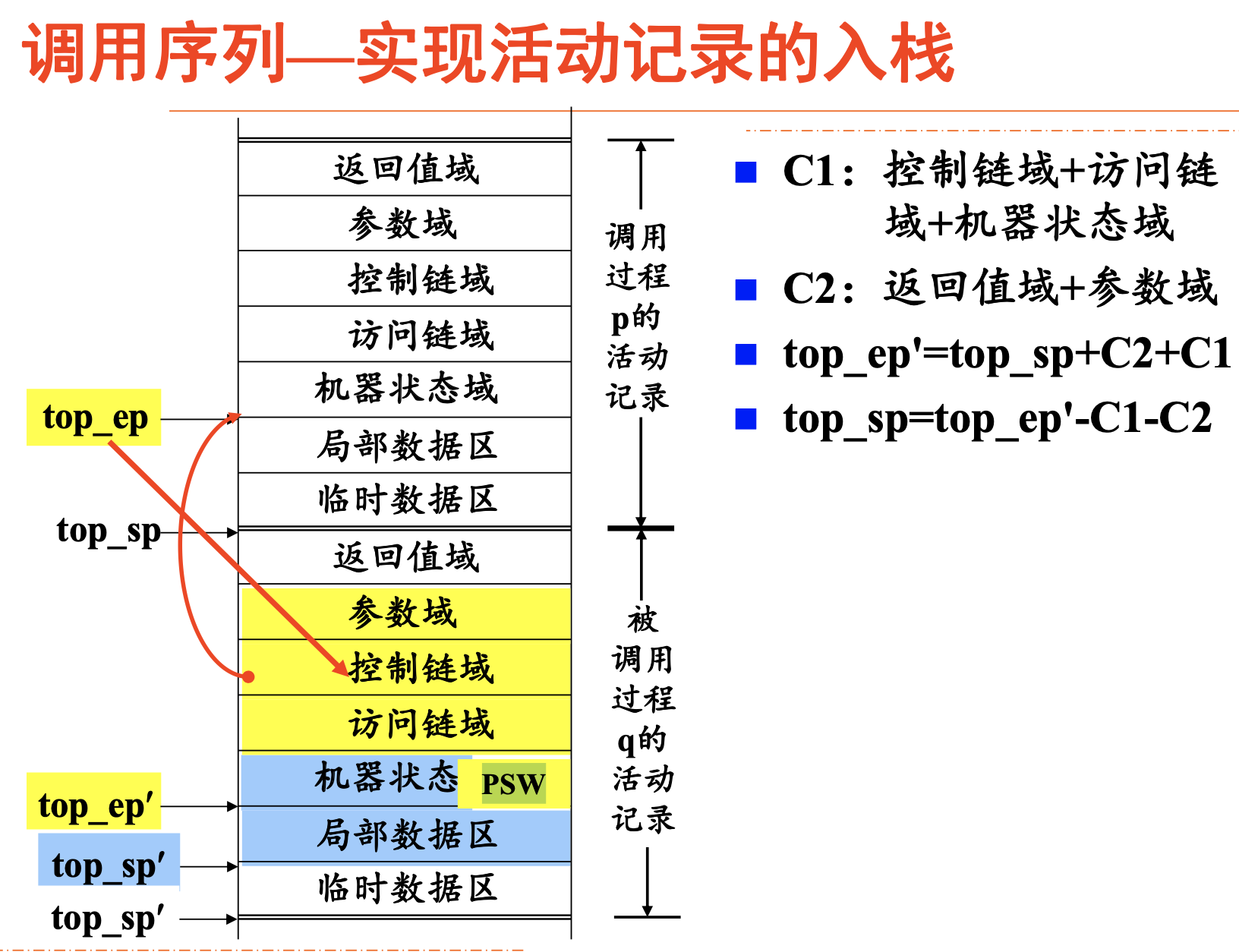
调用序列的安排
-
参数传递
- P准备实参,参数传递入q的活动记录的参数域;
-
控制信息设置
- p将返回地址写入q的活动记录的机器状态域中;
- p将当前top_ep的值写入q的活动记录的控制链域;
- p为q建立访问链;
- P计算并重置top_ep的值**(指向q的活动记录中某位置)**
-
进入q的代码**(goto语句)**
- q保存寄存器的值、其他机器状态信息;
- q增加top_sp的值,初始化局部变量;
- q开始执行
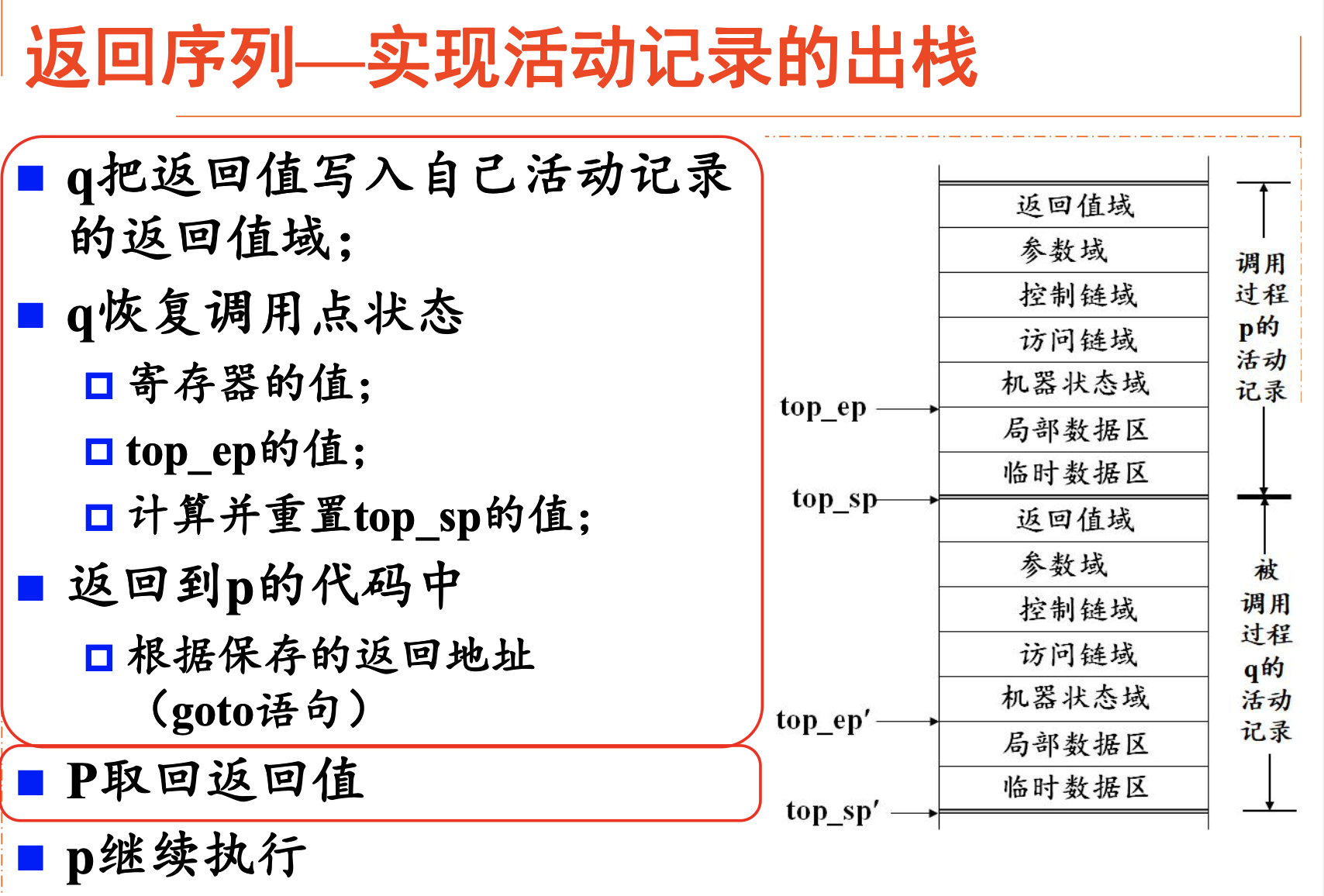
调用序列与活动记录
-
区别
- 活动记录是一块连续的存储区域,保存一个活动所需的全部信息,与活动一一对应。
- 调用序列是一段代码,完成活动记录的入栈,实现控制从调用过程到被调用过程的转移。
- 调用序列逻辑上是一个整体,物理上被分成两部分,分属于调用过程和被调用过程。
-
联系
- 调用序列的实现与活动记录中内容的安排有密切关系。
可变数组的存储分配
某些语言允许由实参的值决定被调用过程中局部数组的大小:可变数组
可变数组所需存储空间的大小,编译时无法确定, 只有在执行到过程调用时,才能根据实参的值确定。
编译时可以确定可变数组的个数
活动记录中只设置相应于可变数组的指针,而不包括这些数组的数据空间
可变数组的数据空间放在活动记录之外。
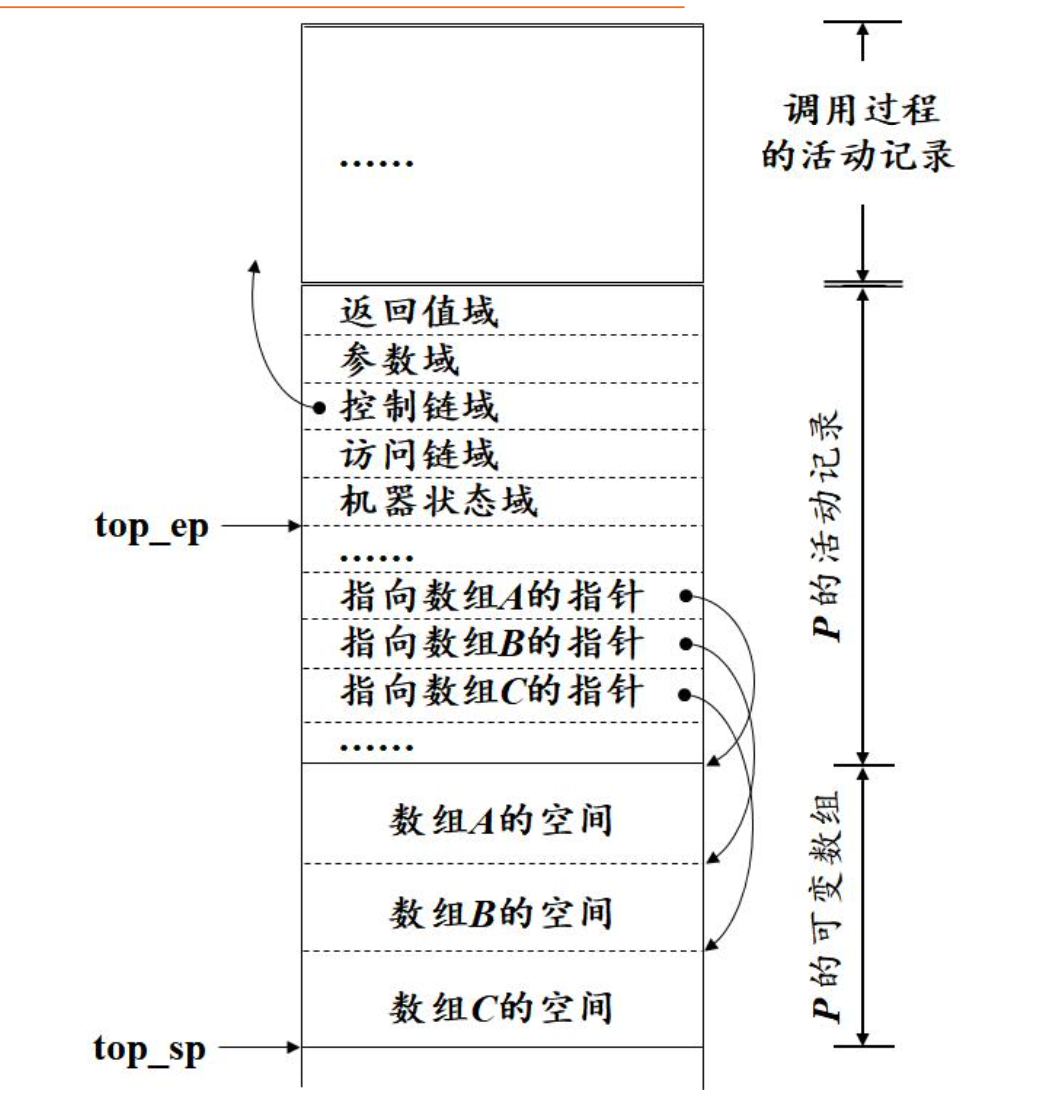
堆式存储分配
如果具体的存储需求在编译时刻可以确定 - 采取静态存储分配策略
如果某些存储需求在编译时不能确定,但在程序执行期间,在程序的入口点上可以知道 - 采用栈式存储分配策略
栈式存储分配策略不能处理的存储需求:
-
活动停止时局部名字的值必须被保存下来;
-
被调用过程的活动生存期超过调用过程的生存期,这种语言的过程间的控制流不能用活动树正确地描述;
-
程序中某些动态数据结构(如链表、树)的存储需求。
它们的共性:活动记录的释放不需要遵循先进后出的原则
堆式与栈式存储分配的比较
相同点:
- 动态存储分配
- 在程序执行期间进行存储分配
不同点:
- 组织形式不同:栈、堆
- 释放顺序
- 栈:后进先出
- 堆:按需、任意
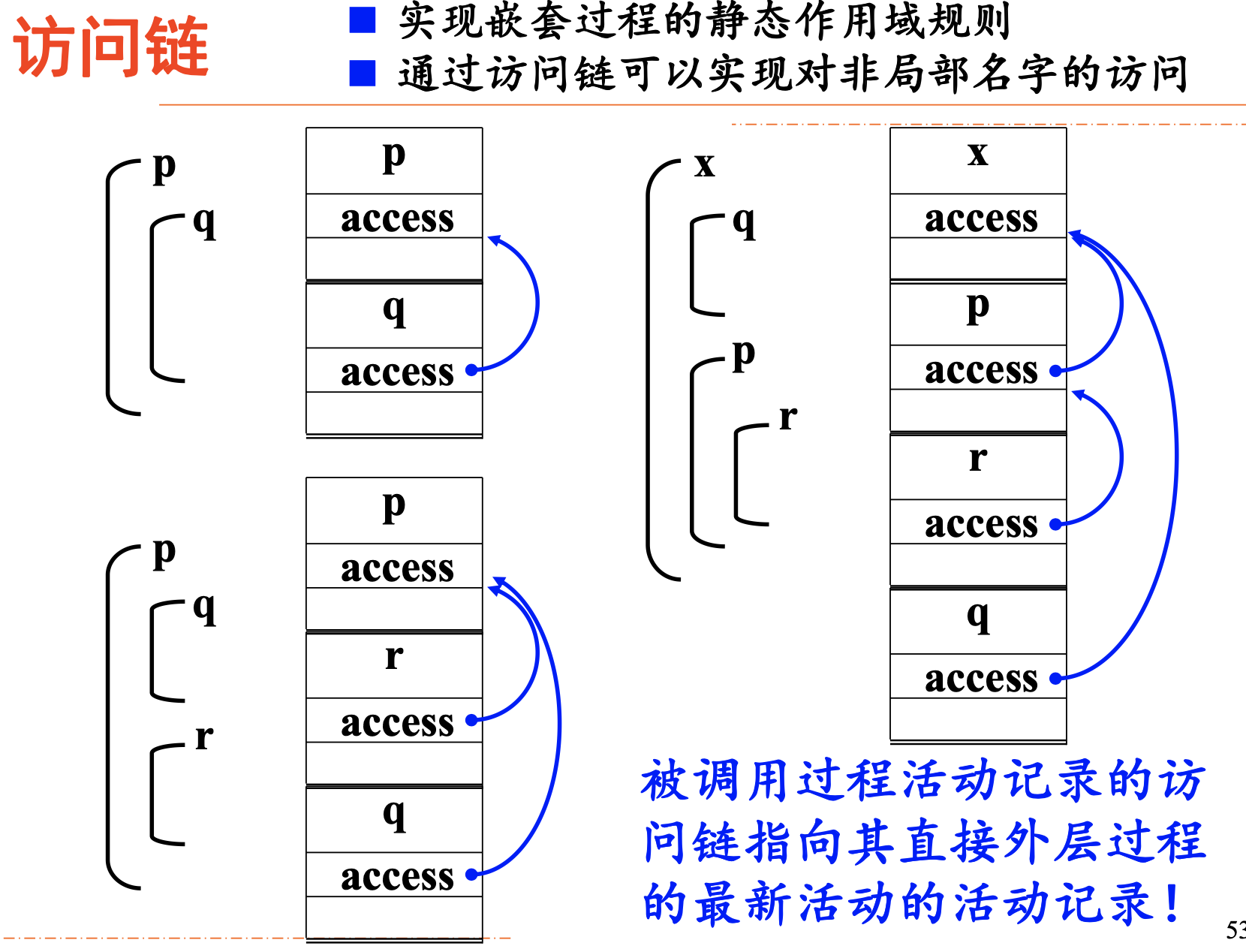
非局部名字的访问
如何处理对非局部名字的引用取决于作用域规则
-
静态作用域规则:词法作用域规则、最近嵌套规则。由程序中名字声明的位置决定。
-
动态作用域规则:由运行时最近的活动决定应用到一个名字上的声明。
对非局部名字的访问通过访问链实现
程序块
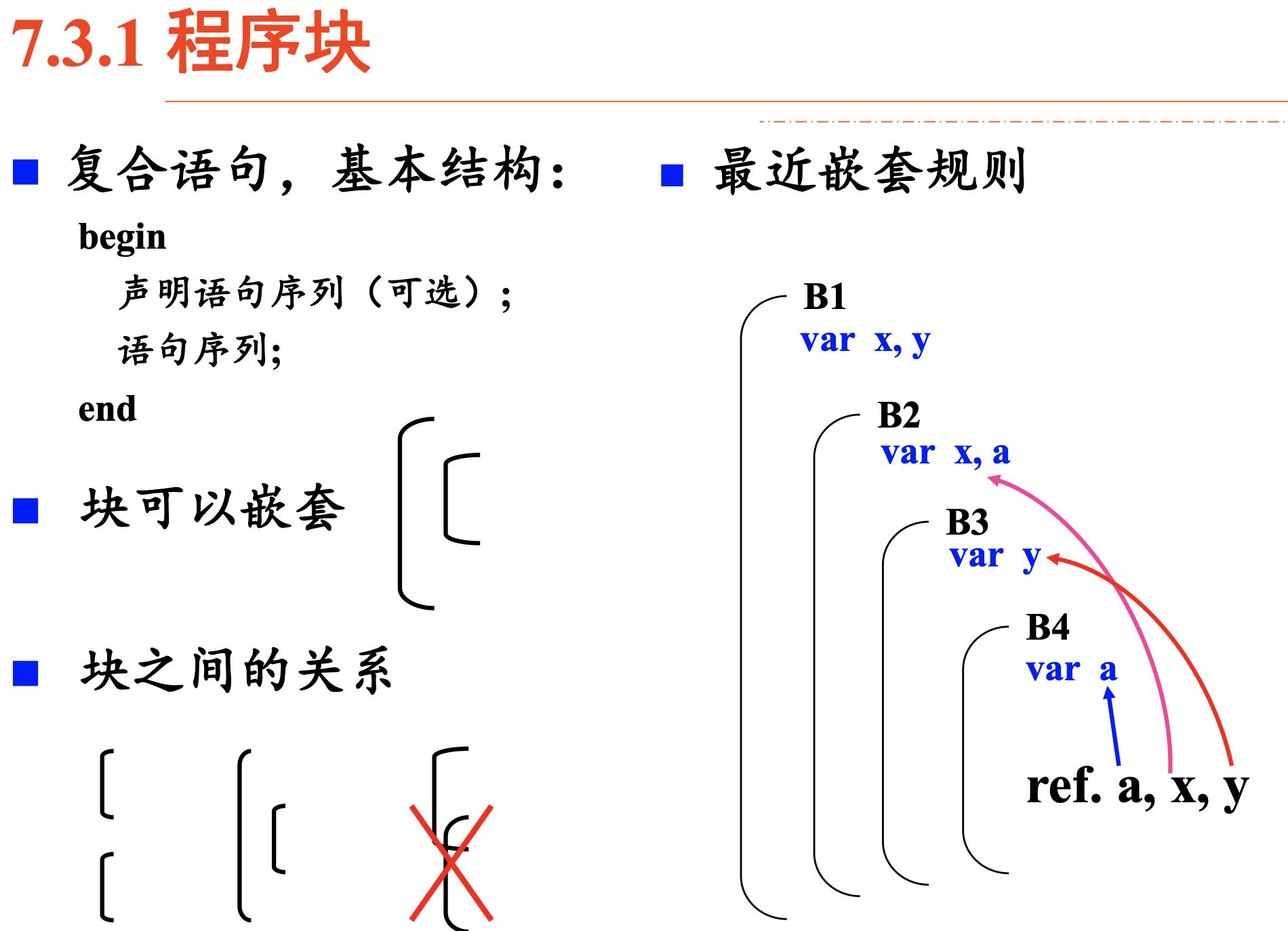
注意最近嵌套规则的定义
静态作用域规则下非局部名字的访问
块结构语言分为两类
- 非嵌套过程语言:
- 过程定义不允许嵌套,即一个过程定义不能出现在另一个过程定义之中。
- 语言代表:C语言
- 嵌套过程语言
- 过程定义允许嵌套
- 语言代表:Pascal语言
程序运行时刻数据空间的分配有差别,且对非局部名字访问的实现方式不同
非嵌套过程语言
嵌套过程语言
嵌套深度
主程序:1
每进入一个过程, 深度加1
最近嵌套规则同样适用于过程名,一个名字的嵌套深度是指它声明时所在过程的嵌套深度
不是引用,而是声明
注意:嵌套关系是指声明时的嵌套深度,而活动记录是调用时才生成

参数传递机制
传值调用
最一般、最简单的参数传递方法。
-
先计算出实参的值,然后将其右值传递给被调用过程。参数值在被调用过程执行时如同常数。
-
用相应的实参的值替代过程体中出现的所有形参。
如:
1
2
3int max(int x,int y) {
return x>y?x:y;
}max(5, 3+4): 将x替换为5,y替换为7,得到5>7? 5:7。
-
函数式语言中唯一的参数传递机制
-
C++、Pascal语言的内置机制。 C语言、Java语言唯一的参数传递机制。
-
在这些语言中,参数被看作是过程的局部变量,初值由调用过程提供的实参给出。
-
在过程中,形参和局部变量一样可以被赋值,但其结果不影响过程体之外的变量的值
引用调用
FORTRAN语言唯一的参数传递机制。
Pascal语言,通过在形参前加关键字var来指定采用引用调用 机制。
1 | procedure inc_1(var x: integer); |
C++中,通过在形参的类型关键字后加符号‘&’指明采用 引用调用机制,如:
1 | void inc_1(int &x) { |
原则上要求:实参必须是已经分配了存储空间的变量。
调用过程把实参存储单元的地址传递给被调用过程的相应形参(即一个指向实参存储单元的指针)。
被调用过程执行时,通过形参间接地引用实参。
可以把形参看成是实参的别名,对形参的任何引用都是对相应实参的引用。
C语言只有传值调用机制,但可以通过传递引用或显式指针 来实现引用调用的效果。
C语言使用‘&’指示变量的地址,使用操作‘*’撤销引用 指针。
引用调用的实现
调用过程对实参求值。
- 如果实参是具有左值的名字或表达式,则传递这个左值本身。
- 如果实参是没有左值的表达式(如 a+b 或 2 等), 则为它申请一临时数据空间,计算出表达式的值并存入该单元,然后传递这个存储单元的地址。
把实参的左值写入被调用过程活动记录中相应形参的存储单元中。
被调用过程执行时,通过形参间接地引用实参
复制恢复
传值调用和引用调用的一种混合形式
复制恢复机制的实现
- 过程调用时,调用过程对实参求值,将实参的右值传递给被调用过程,写入其活动记录的参数域中(copy in),并记 录与形参相应的实参的左值。
- 被调用过程执行时,对形参的操作在自己的活动记录的参数域空间上进行。
- 控制返回时,被调用过程根据所记录的实参的左值把形参的当前值复制到相应实参的存储空间中(copy out) 。当然, 只有具有左值的那些实参的值被复制出来。
传名调用
Algol 60语言所定义的一种特殊的参数传递方式。
传名调用机制
把过程当作“宏”处理,即在调用出现的地方,用被调用过程的过程体替换调用语句,并用实参的名字替换相应的形参。这种文字替换称为宏扩展。
被调用过程中的局部名字不能与调用过程中的名字重名。 可以考虑在做宏扩展之前,对被调用过程中的每一个名字都系统地重新命名,即给以一个不同的新名字。
为保持实参的完整性,可以用括号把实参的名字括起来
哥们的Trinity也是捏







