
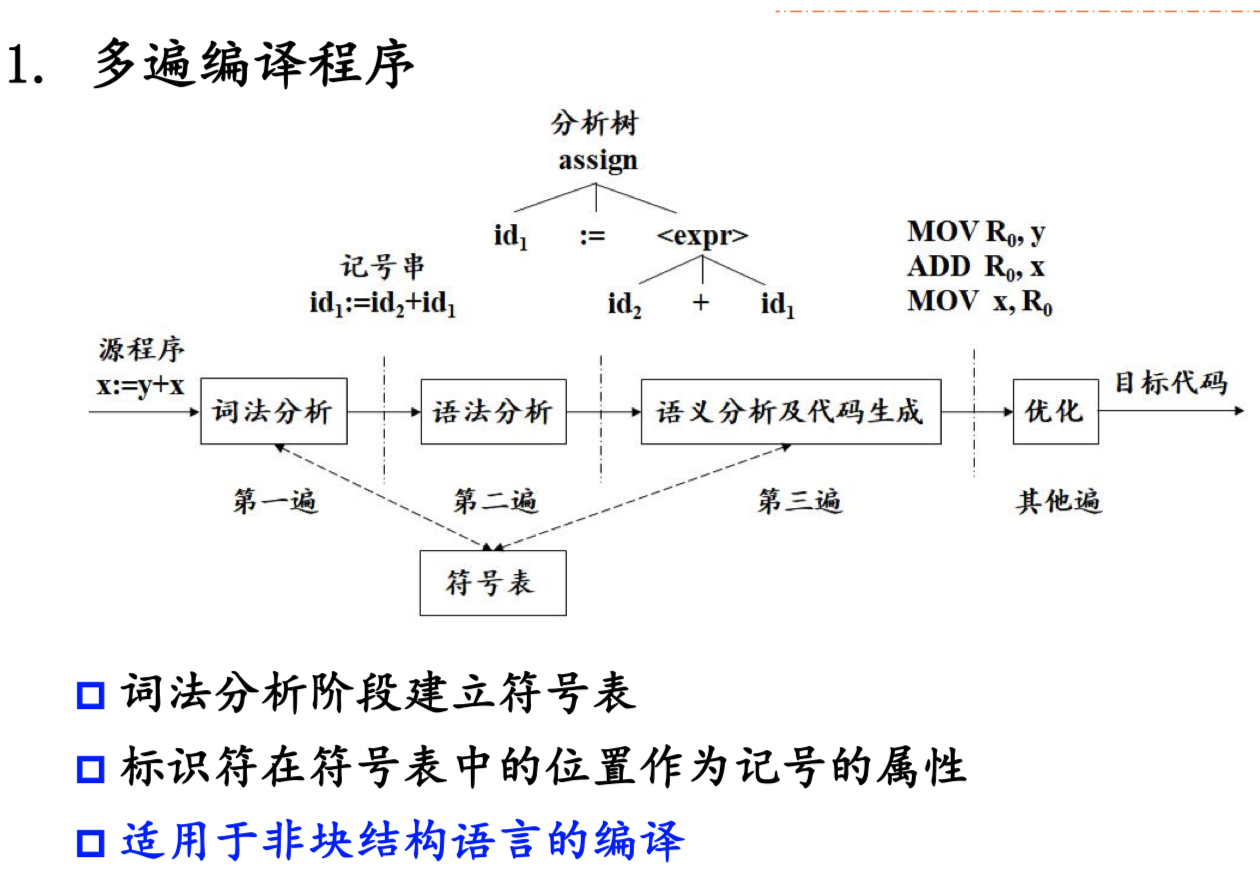
编译原理 期末复习 语义分析
语义分析
概述
可以使用上下文无关文法来描述语言中上下文有关的结构,但是理论可行,构造上十分困难,需要利用语法制导翻译技术实现语义分析,或设计专门的语义动作补充上下文无关文法的分析程序
语义分析的任务
-
语义分析程序通过将变量的定义与变量的引用联系起来,对源程序的含义进行检查。 检查每一个语法成分是否具有正确的语义。
-
语义分析的任务
- 收集并保存上下文有关的信息
- 类型检查
符号表
- 在分析声明语句时,收集所声明标识符的有关信息,如类型、存储位置、作用域等,并记录在符号表中
- 只要编译时控制处于声明该标识符的程序块中,就可以从 符号表中查到它的记录
类型检查
- 动态检查:目标程序运行时进行的检查
- 静态检查:读入源程序但不执行源程序的情况下进行的检查
- 由类型检查程序完成
检验结构的类型是否与其上下文所期望的一致、检查操作的合法性和数据类型的相容性
- 内部函数 mod 的运算对象的类型
- 表达式中各运算对象的类型
- 用户自定义函数的参数类型、返回值类型
唯一性检查
- 一个标识符在同一作用域中必须且只能被说明一次
- CASE语句中用于匹配选择表达式的常量必须各不相同
- 枚举类型定义中的各元素不允许重复
控制流检查
- 检查控制语句是否使控制转移到一个合法的位置
语义分析程序的位置
-
以语法树为基础,根据源语言的语义,检查每个语法成分在语义上是否满足上下文对它的要求。
-
输出:带有语义信息的语法树
语义分析的结果有助于生成正确的目标代码
-
重载运算符:在不同的上下文中表示不同的运算
-
类型强制:编译程序把运算对象变换为上下文所期望的类型
错误处理
语义相关的错误:
- 同一作用域内标识符重复声明
- 标识符未声明
- 可执行语句中的类型错误
错误处理:
- 显示出错信息。报告错误出现的位置和错误性质
- 错误恢复。恢复分析器到某同步状态, 为了能够对后面的结构继续进行检查
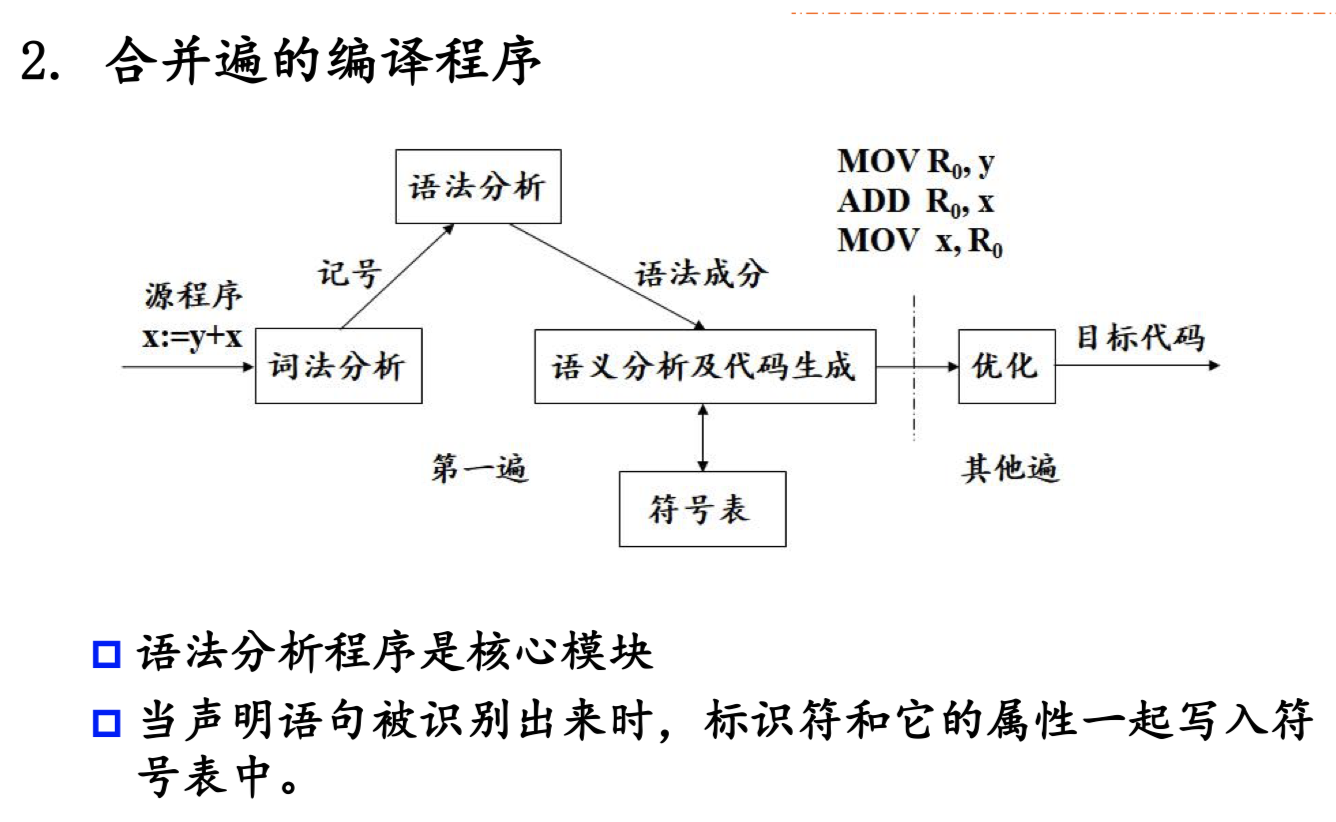
符号表
符号表在翻译过程中起两方面的重要作用
- 检查语义(即上下文有关)的正确性
- 辅助正确地生成代码
通过在符号表中插入和检索标识符的属性来实现
符号表是一张动态表,在编译期间符号表的入口不断地增加,在某些情况下又在不断地删除。编译程序需要频繁地与符号表进行交互,符号表的效率直接影响编译程序的效率
符号表的建立与访问时机
符号表操作
最常执行的操作:插入和检索
要求标识符显式声明的强类型语言
-
编译程序在处理声明语句时调用两种操作
-
检索:查重、确定新表目的位置
-
插入:建立新的表目
-
-
在程序中引用名字时,调用检索操作
- 查找信息,进行语义分析、代码生成
- 可以发现未定义的名字
允许标识符隐式声明的语言
- 标识符的每次出现都按首次出现处理
- 检索:
- 已经声明,进行类型检查
- 首次出现,插入操作,从其作用推测出该变量的相关属性
定位和重定位操作
对于块结构的语言,在建立和删除符号表时还要使用两种附加的操作,即定位和重定位。
定位操作
当编译程序识别出块开始时,执行定位操作
建立一个新的子表(包含于符号表中),在该块中声明的所有名字的属性都存放在此子表中。
重定位操作
当编译程序遇到块结束时,执行重定位操作。“删除”存放该块中局部名字的子表。
这些名字的作用域局部于该块,出了该块后不能再被引用
符号表组织
非块结构语言的符号表组织
不讲不学
块结构语言的符号表组织
块结构语言:
- 模块中可嵌套子块
- 每个块中均可以定义局部变量
每个程序块有一个子表,保存该块中声明的名字及其属性。
符号表组织
- 栈式符号表
- 栈式哈希符号表
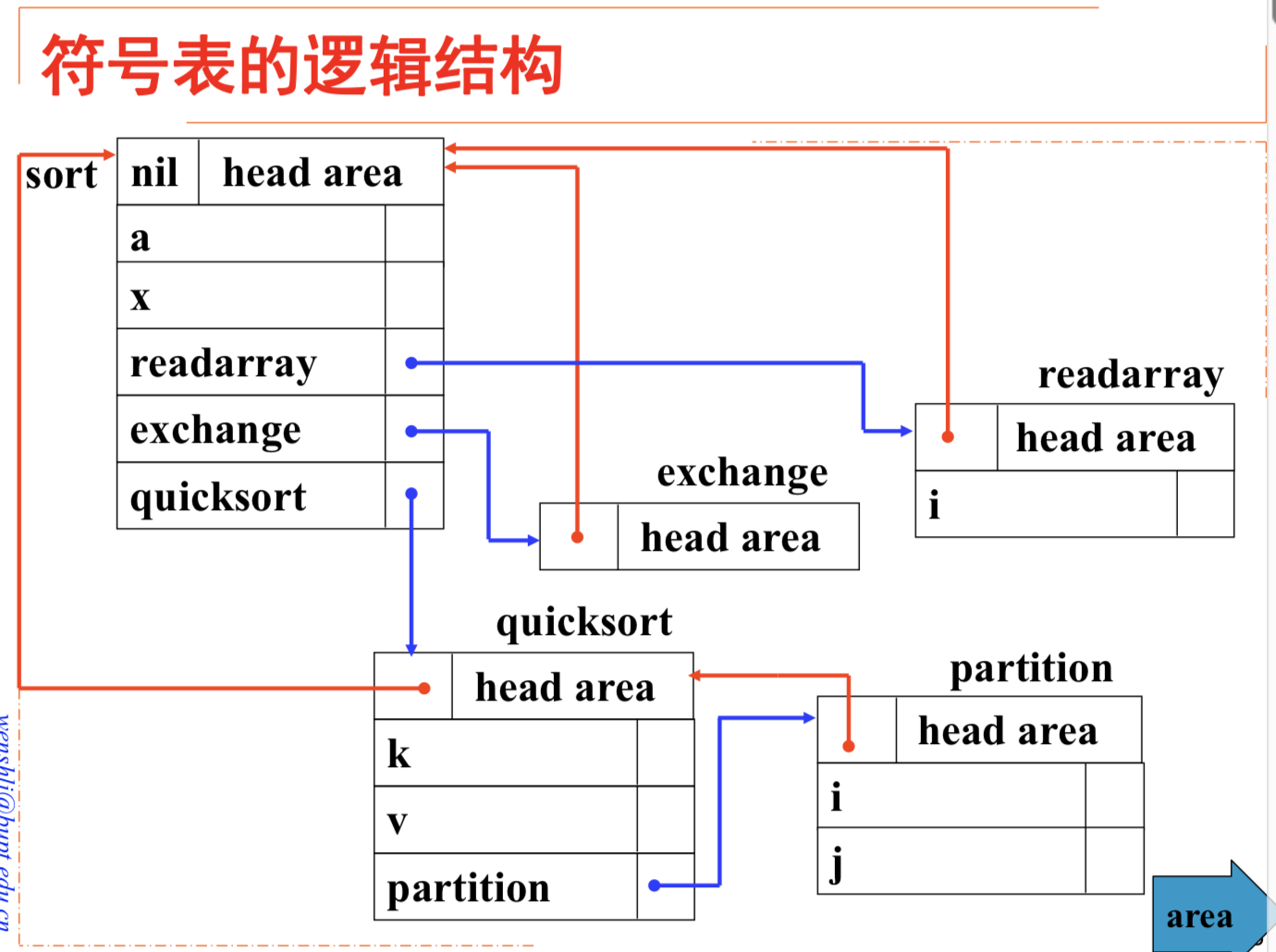
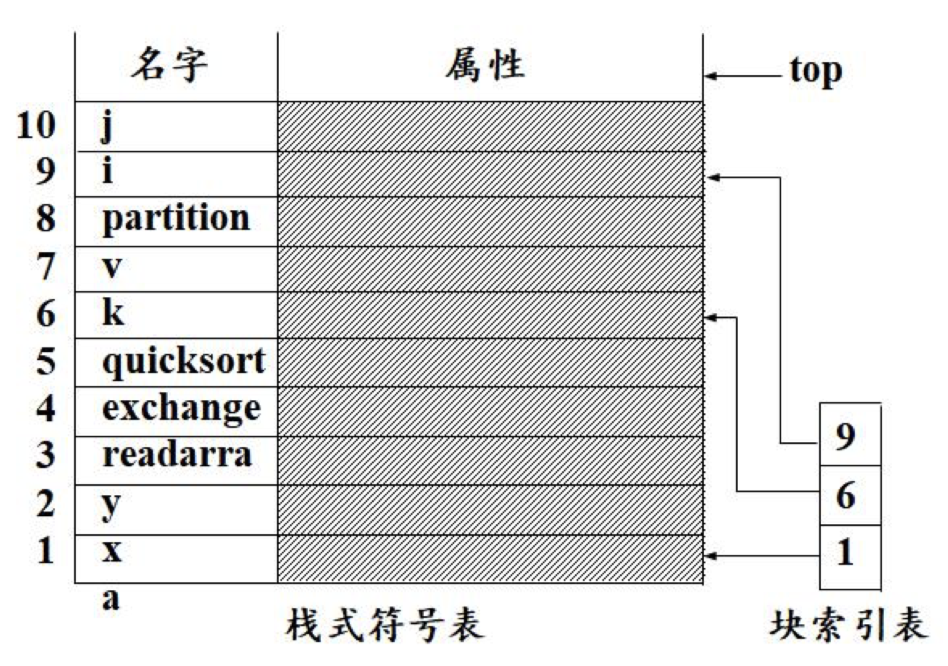
栈式符号表
- 当遇到变量声明时,将包含变量属性的记录入栈
- 当到达块结尾时,将该块中声明的所有变量的记录出栈
插入
检查子表中是否有重名变量
- 无,新记录压入栈顶
- 有,报告错误
检索
从栈顶到栈底线性检索
- 在当前子表中找到,局部变量
- 在其他子表中找到,非局部名字
实现了最近嵌套作用域原则
定位
也就是进入新的一层子块
- 将栈顶指针top的值压入块索引表顶端。
- 块索引表的元素是指针,指向相应块的子表中第一个记录在栈中的位置。
重定位
也就是退出一个子块回到上一层
- 用块索引表顶端元素的值恢复栈顶指针top,完成重定位操作
- 有效地清除刚刚被编译完的块在栈式符号表中的所有记录
栈式哈希符号表
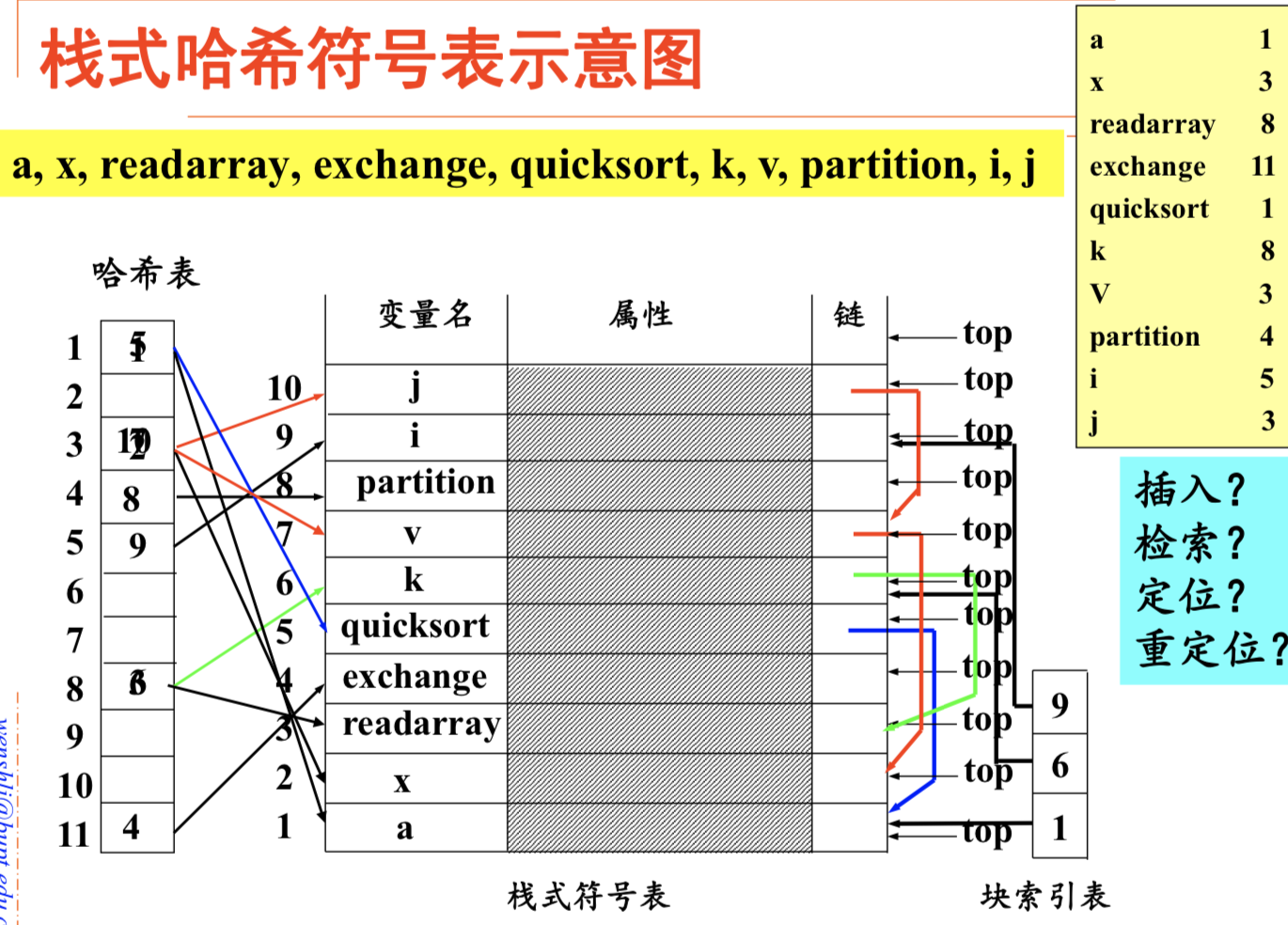
链的作用是当哈希表发生冲突时,建立同一哈希值的符号联系
类型检查
静态类型检查:由编译程序完成的检查
动态类型检查:目标程序运行时完成的检查
如果目标代码把每个对象的类型和该对象的值一起保存, 那么任何检查都可以动态完成
一个健全的类型体制不需要动态检查类型错误。
如果一种语言的编译程序能够保证它所接受的程序不会有运行时的类型错误,则称这种语言是强类型语言
有些检查只能动态完成
显式类型
- 可提高程序的可读性,有助于理解程序中每一个数据结构的作用,及其所允许的操作
- 去除运算符的重载。
静态类型
- 编译程序更有效地进行存储分配、产生高效的机器代码。
- 可提高编译效率。
- 使用静态接口类型,通过证明接口一致性和正确性,可以提高大型程序的开发效率。
显式类型和静态类型检查相结合
- 可尽早检出标准程序错误、减少可能出现的执行错误
- 编译时发现不正确的程序设计
大多数现代程序设计语言都使用显式类型,由编译程序进行静态类型检查
类型表达式
- 语法结构
- 数据类型
- 类型体制(把类型指派给语法结构的规则)
每一个表达式有一个类型
类型有结构
凡有类型的语言:
-
都有一套类型声明规则。
-
基本类型,即对程序员来说没有内部结构的类型,如 integer、char、boolean等。
-
类型构造器,即类型运算符,程序员利用类型构造器可以由基本类型构造新的有结构的类型,称为构造类型。 可以由具有简单结构的构造类型构造新的具有更复杂结构的构造类型
-
由类型构造器创建的新的类型不是自动获得名字的,新类型的名字由类型声明创建(typedef)
类型体制
-
把类型表达式指派到程序各语法结构的一组规则
-
由类型检查程序实现
-
同一语言的不同编译程序使用的类型体制可能不同
类型表达式的递归定义
-
基本类型是类型表达式(integer,char,boolean,real,type_error,void)
-
类型名是类型表达式,因为类型表达式可以命名
-
类型构造器作用于类型表达式的结果仍是类型表达式
-
数组
array(1…10,integer)
-
笛卡尔积
-
记录
结构体和联合体
举例:
1
2
3
4struct A {
int num;
real weight;
}类型表达式为
-
指针
pointer(integer)
-
函数
1
int main(int A,char C)
类型表达式为
-
类型表达式中可以包含变量(称为类型变量),变量的值是类型表达式
-
类型等价
结构等价
如果两个数据类型具有相同的结构,即都是从相同 基本类型出发、用相同的类型构造器由完全相同的方法构造出来的,那么它们就是结构等价的
实际应用中,数组的界(范围)不作为类型的一部分
名字等价
编程语言允许用户自定义类型名(typedef)
对于struct和union采用名字等价,其他采用结构等价
注意:pascal和c语言类似,类型构造器(如记录、数组、指针等)的每次应用,都将产生一个新的内部名字
也就是说,每次定义除了struct和union外的变量,认为它们等价
如
2
3
4
5
6
7
8
9
10
11
12
13
14
int age;
} recA
typedef recA *recP
recP a;
recP b;
recA *c,*d
recA *e认为 a,b等价
c,d等价
但a,c,e不等价
符号表的建立
声明语句的处理
翻译目标
- 识别出被声明的实体
- 记录实体的名字、类型、在数据区中的位置
引入
- 全局变量offset,记录相对地址
- T.width:记录实体的域宽
- T.type:记录实体的类型
- enter(id.name,T.type,offset)

offset为下一个变量的相对地址,每次定义变量后会以这个变量的大小的距离移动
过程定义的处理
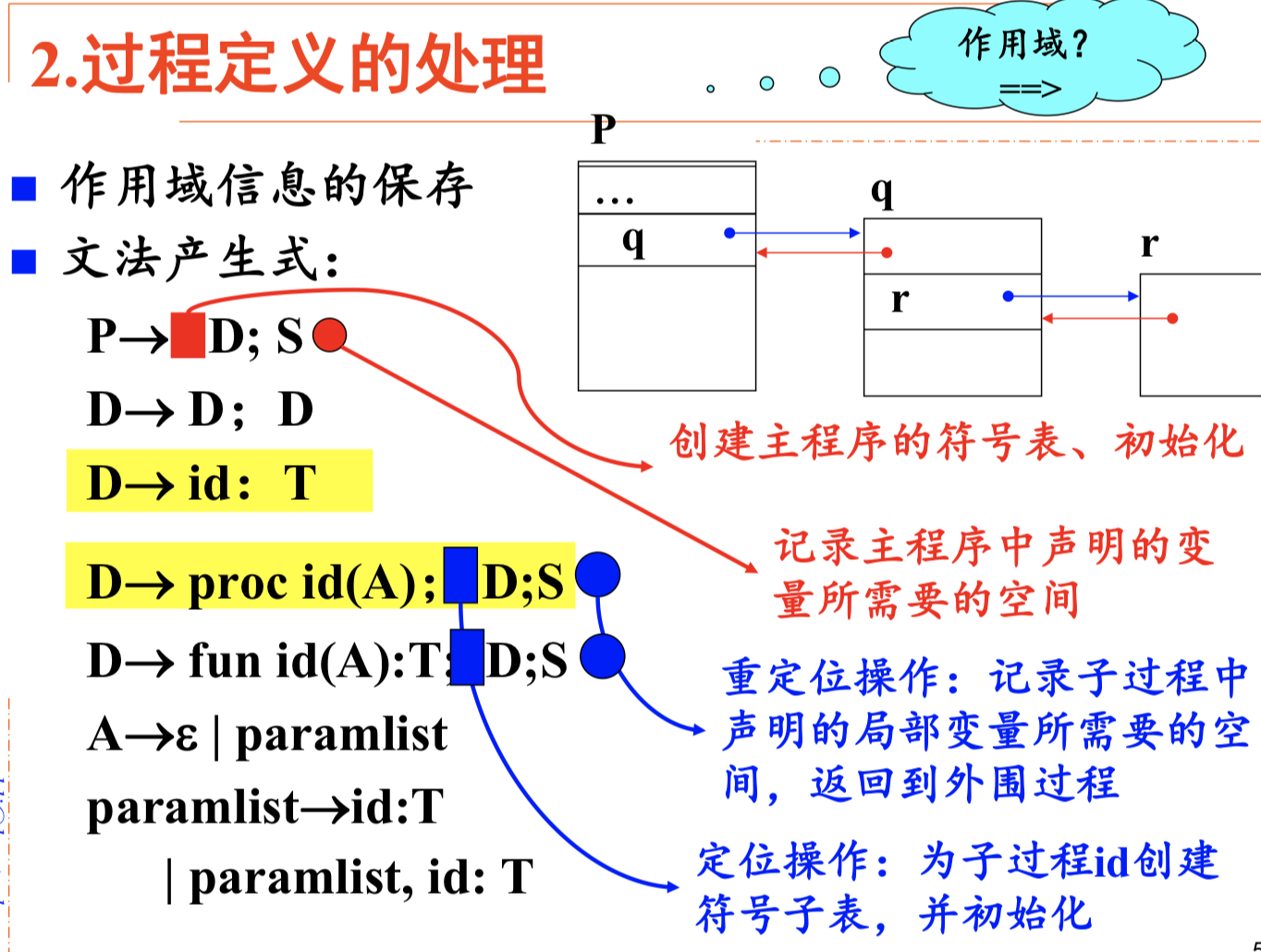
S指的是可执行程序
用栈记录符号表嵌套关系,且便于操作
记录声明的处理
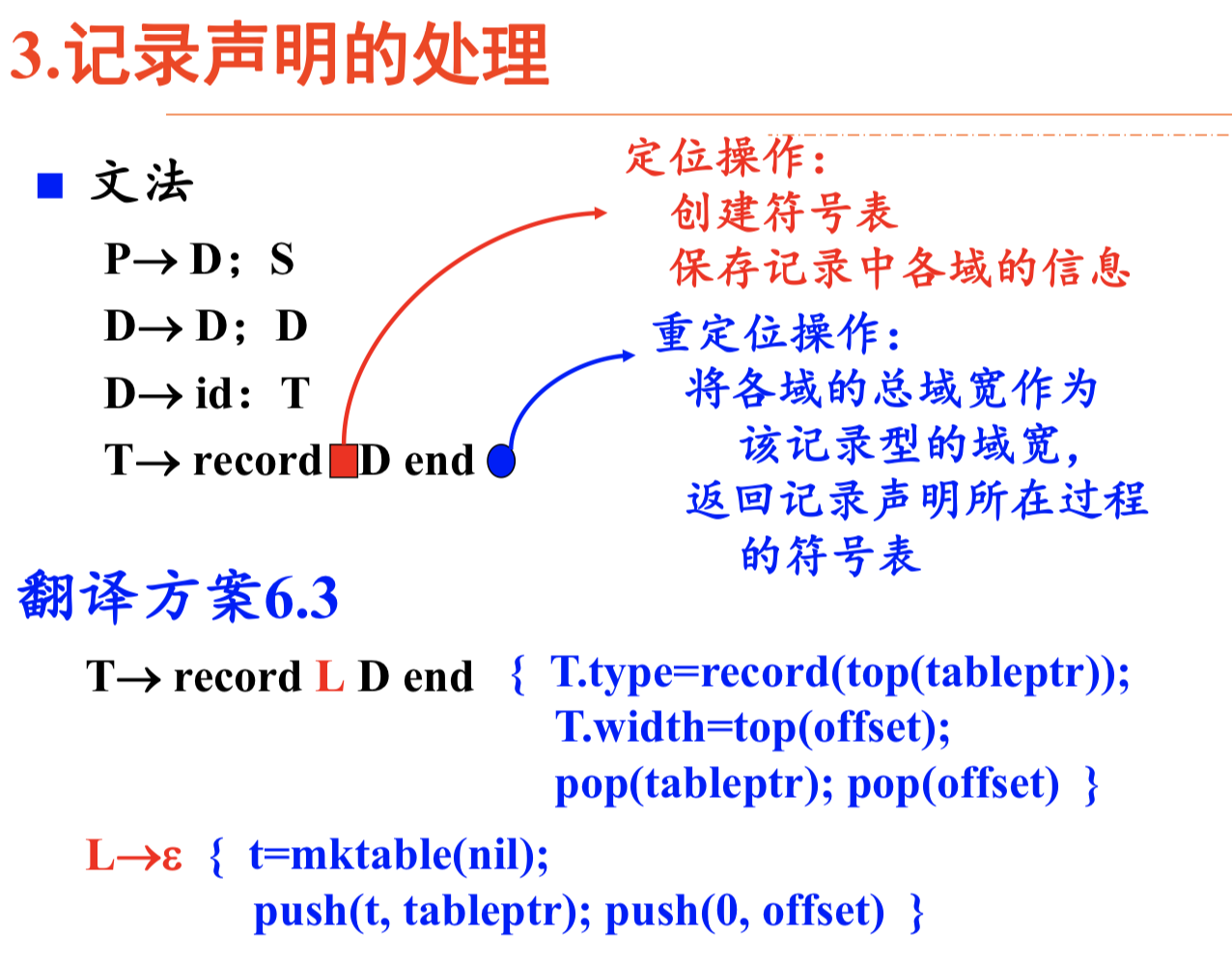
记录即为结构体、联合等复合类型,声明时相当于进入一个子函数
表达式的类型检查
对于声明变量,直接检查
对于赋值变量,从符号表中找到对应的符号
对于语句,若没有类型错误指派void,否则指派type_error
类型转换
不同类型的数据对象在计算机中的表示形式不同。
用于整型运算和实型运算的机器指令不同。
当不同类型的数据对象出现在同一表达式中时,编译程序必须首先对其中的一个操作数的类型进行转换,以保证在运算时两个操作数的类型是相同的。
如果类型转换构建在类型体制中,由编译程序完成,这种类型转换是隐式的,称做强制转换或隐式转换
如果类型转换必须由程序员显式地写在源程序中,则这种转换叫做显式转换
常数的类型转换
常数的类型转换可以在编译时完成,并且常常可以使目标程序的运行时间大大改进。
如:float x;
x=1 的执行时间比 x=1.0 的要长







