
数据库系统原理 期末复习(四)
第17章 事务
一个事务是一系列有序操作的集合
ACID属性
事务有以下属性(ACID Properties):
- 原子性 Atomicity(事务不会因为中断而只执行到一半,要么做完要么取消)
- 一致性 Consistency(操作不会产生意外作用)
- 隔离性 Isolation(并发执行不会互相干扰)
- 持久性 Durability(操作永久生效,作用不会突然消失)
原子性由事务管理控制保证
一致性由前端事务设计者保证
隔离性由并发控制机制保证
持久性由恢复控制机制保证
事务状态
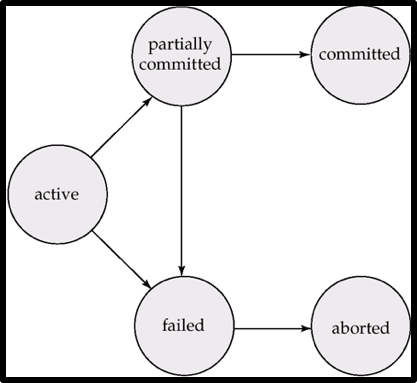
Active
基态,事务保持在这个状态,直到它开始执行
Partially committed
最后一句操作语句执行结束后,进入该状态
Failed
当发现无法正常执行后,进入该状态
Aborted
如果没有逻辑错误,会重启事务
当然,也可以杀掉事务
Commited
成功提交后,进入该状态
并发
- 提高资源使用效率
- 减少事务平均响应时间
调度
安排事务并发操作的时间先后顺序
- 有序性(绝对操作顺序不能更改)
- 完整性(所有操作都要调度)
串行调度 serial schedule

并发调度 concurrent schedule

不恰当的并发调度会引起结果的不一致
可串行化的并发调度 Serializability
一个可串行化的并发调度等价于一系列的串行调度
冲突可串行化 Conflict Serializability
如果两个操作执行顺序先后不同会导致结果不同,称为冲突操作
- 写 - 写冲突
- 读 - 写冲突
- 写 - 读冲突
读 - 读 和 对不同数据项的操作不会冲突
如果对一个调度,通过调换非冲突操作的顺序后,该调度等价于另一个调度,称这两个调度是冲突等价
如果一个并发调度通过调换后等价于一个串行调度,称它为冲突可串行化的
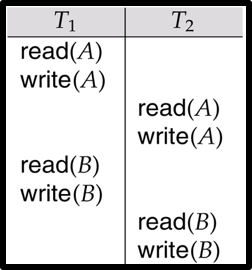
如上图,可以把T1对B的读写调换到T2对A的读写前,不会发生冲突,则它是冲突可串行化的
可以用图的方式判断:
G(V,E)
构造一条有向边,当且仅当以下情况之一发生时:
- Ti executes write(Q) before Tj executes read(Q);
- Ti executes read(Q) before Tj executes write(Q);
- Ti executes write(Q) before Tj executes write(Q);
如果构造出的有向图中存在自环,则不是冲突可串行化的
对于可以冲突可串行化的图,采用拓扑排序进行串行化的排序

- 首先,寻找入度为0的节点,开始排序
- 去掉这个节点与它的边,重复第一步
- 直到排序完为止
1 - 3 - 2 - 4
可恢复的调度
如果一个事务B读了事务A写的数据,那么B的提交必须在A的提交之后,这样的调度才是可恢复的调度

级联调度

10的回滚会导致11的回滚,11的回滚会导致12的回滚
要求一个事务读其他事务写的数据,读操作要发生在其他事务提交后,才能避免级联调度,也就是无级联调度(cascadeless schedule)
无级联调度一定是可恢复的调度,但是反过来不一定
可能遇到的问题
脏读:读到了别的事务回滚前的脏数据。
不可重复读:当前事务先进行了一次数据读取,然后再次读取到的数据是别的事务修改成功的数据,导致两次读取到的数据不匹配。
幻读:当前事务读第一次取到的数据比后来读取到数据条目不一致。事务A首先根据条件查询得到N条数据,事务B改变了这N条数据之外的M条或者增添了M条符合事务A查询条件的数据,导致事务A再次搜索发现有N+M条数据了,就产生了幻读。
Serializable (可串行化):最严格的级别,事务串行执行,资源消耗最大;
REPEATABLE READ(重复读) :在开始读取数据(事务开启)时,不再允许修改操作
避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”。
READ COMMITTED (提交读):一个事务要等另一个事务提交后才能读取数据
避免了“脏读”,但不能避免“幻读”和“不可重复读取”。
Read Uncommitted(未提交读) :一个事务可以读取其他事务未提交的数据
会导致“脏读”、“幻读”和“不可重复读取”。
第18章 并发控制
两阶段锁 + 严格两阶段锁 + 强两阶段锁
多粒度锁 锁的相容性矩阵 加锁能加吗
死锁 两个预防协议
隔离性
基于锁的并发控制
共享锁与互斥锁
exclusive lock 互斥锁 写之前要申请,可读写
shared lock 共享锁 读之前申请,只能读
它们的关系如下:

死锁
互相等待
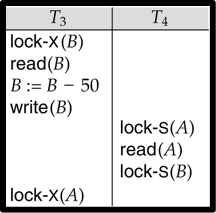
3对B上了互斥锁,4无法上共享锁,于是等待
饥饿问题
总有事务给目标项上锁导致当前事务一直等待上锁
两阶段锁协议
针对一个事务来说:
锁的增长阶段
- 可以申请锁
- 不能释放锁
锁的缩减阶段
从释放第一把锁开始,进入该阶段
- 可以释放锁
- 不能申请锁
两阶段锁协议可保证冲突可串行化,等价于锁点发生的顺序的串行化
锁点:事务获取最后一把锁的时间点
但是,不能避免死锁,也不能避免级联回滚
以上会级联回滚
解决级联回滚:提交后再释放锁
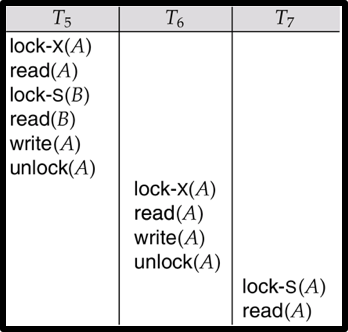
严格两阶段锁协议
将互斥锁保持到提交或停止后才释放
强两阶段锁协议
所有的锁必须保持,直到提交或停止后才释放
这样可以解决级联回滚问题,保证冲突可串行化。
升级与降级
锁的增长阶段
- 可以申请锁
- 不能释放锁
- 还可以将共享锁升级为互斥锁
锁的缩减阶段
从释放第一把锁开始,进入该阶段
- 可以释放锁
- 不能申请锁
- 还可以将互斥锁降级为共享锁
多粒度锁 Multiple Granularity
锁可以对一张表,一行,一项
低粒度锁会导致效率提高,但管理困难
高力度锁会导致效率较低,管理方便
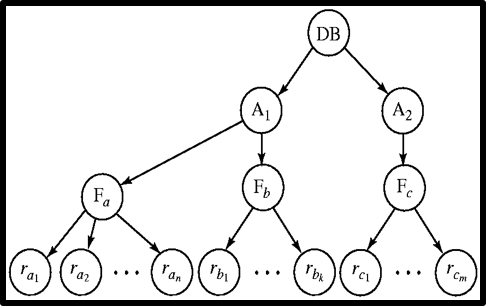
高层的锁会隐式影响低层的锁,故对低层锁的操作需要判断高层有无加锁,判断复杂,所以需要多粒度锁分层设置
intention lock 意向锁
反映的是当前节点的子节点要加锁的意向
意向锁的含义是如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任一结点加锁时,必须先对它的上层结点加意向锁。
intention-shared 意向共享锁
intention-exclusive 意向互斥锁
shared and intention - exclusive 共享-意向互斥锁
对节点自身要加共享锁,子节点要加互斥锁
反映的是同一个事务的情况
现在,只需要判断从根节点到该节点的情况,不需要判断子节点,节省开销
关系矩阵
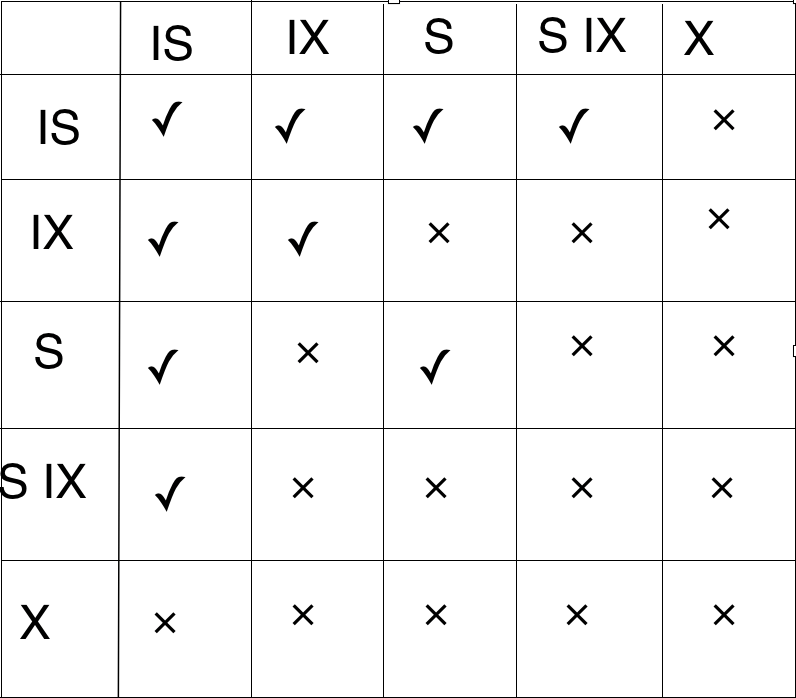
在子节点全部会冲突的,该节点冲突,需要等待
在子节点有可能不冲突的,该节点相容,留给子节点判断
加锁顺序
- 从根节点开始向下加上意向锁,只有上级节点有意向锁才能给子节点加上意向互斥锁
解锁顺序
- 从叶子节点向上一层层解锁,直到根节点
死锁
预防死锁
-
申请锁,需要全部申请到才能进行操作,如果有申请失败的就全部释放
-
超时机制
-
避免一些会导致死锁的申请顺序
-
等待死亡协议(非抢占,永远让年老的等年轻的,如果有年轻的等年老的就回滚)
If TS(Ti) < TS(Tj)
then Ti Waits // 如果Ti存在时间更长就等待
Else
RollBack Ti // 否则就回滚Ti
Tj执行中…
Restart Ti with the same TS(Ti) // 重启Ti,时间与之前一致
Endif
存在可能的情况:Ti再次判断时,Tj未执行完,造成重复回滚,但是不会抢占事务
-
伤害等待协议(抢占,永远让年轻的等年老的,如果有年老的等年轻的就回滚)
If TS(Ti) > TS(Tj)
then Ti Waits
Else
RollBack Tj
Ti执行中…
Restart Tj with the same TS(Tj)
Endif
存在可能的情况:回滚正在正常执行的年轻的事务,伤害年轻的事务
检测死锁
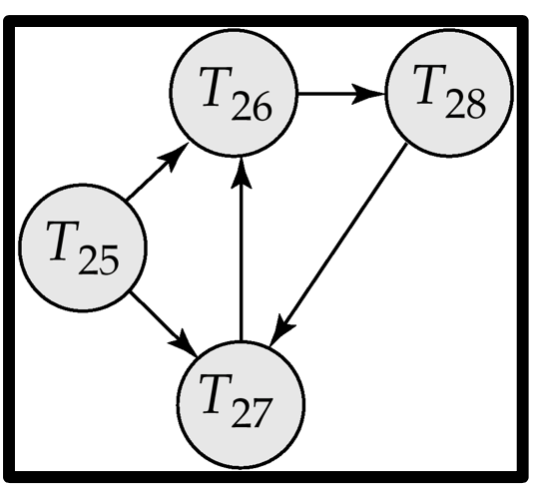
B需要A占用的数据,就有一条有向边从A指向B
为了避免同一个节点被重复抽中,可以设置保底机制,加权值等
第19章 恢复
-
事务故障
- 逻辑错误
- 系统错误
-
系统崩溃
失败停止假设:崩溃后数据不会丢失
-
磁盘故障
恢复算法
- 未崩溃前,进行备份(基于日志的备份)
- 崩溃后,及时恢复
存储结构
易失介质 - 内存
不易失介质 - 磁盘、磁带、非易失RAM
稳定永不消失介质 - RAID
数据的读取与写入
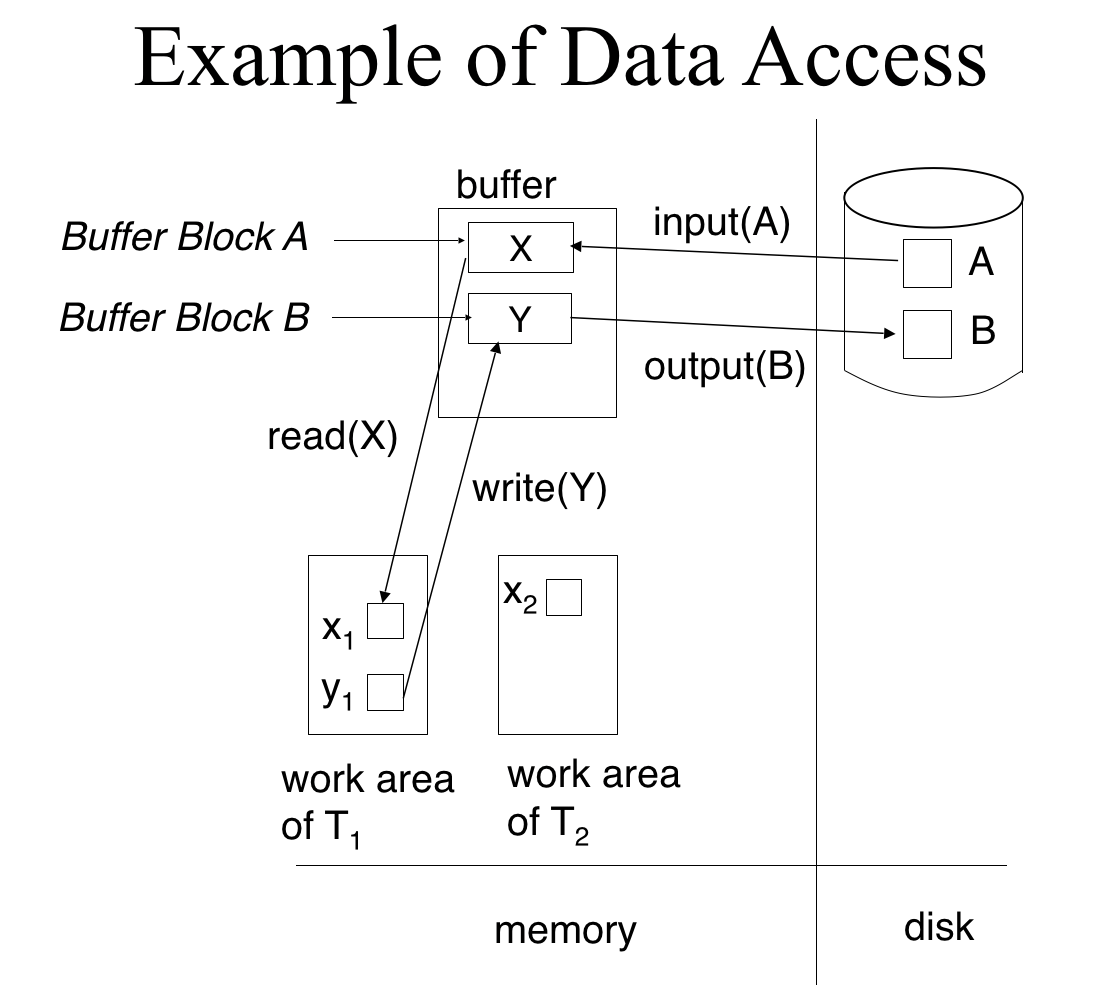
- read - 从缓冲区读入记录到数据库中
- write - 向缓冲区写入记录
- input - 从磁盘读入数据到缓冲区中
- output - 向磁盘写入数据
假设已经完成write,但是缓冲区未及时output就崩溃,此时记录会丢失,此时需要恢复
基于日志的恢复
假设日志是不会丢失的,数据库是即时更新的
-
<Ti start>
-
<Ti, X, V1, V2>
X是数据项,V1是操作前的状态,V2是操作后的状态
-
<Ti commit>
-
<Ti abort>
必须在进行操作前先更新日志
- 撤销操作 - 数据项改成修改前的版本
- 重做操作 - 数据项改成修改后的版本
操作具有幂等性 - 也就是说,多次操作的结果是一样的,因为日志记录的是操作前后的状态而不是过程
为了防止多次崩溃,可以多次回滚操作,直到回滚到<Ti start>
或者,可以从日志自近向远回滚,最后写上<Ti abort>表示终止
总的来说,如果只有start没有commit或abort,就undo到start
如果有start与对应的commit或abort(事务逻辑已经完成),就redo
检测点 checkpoint
记录下检测点,可以从最近的检测点开始恢复
在完成一次undo或者redo后,将所有日志记录放置到安全的存储介质去,将缓冲区数据写入磁盘,然后设置<checkpoint>来记录一个检测点
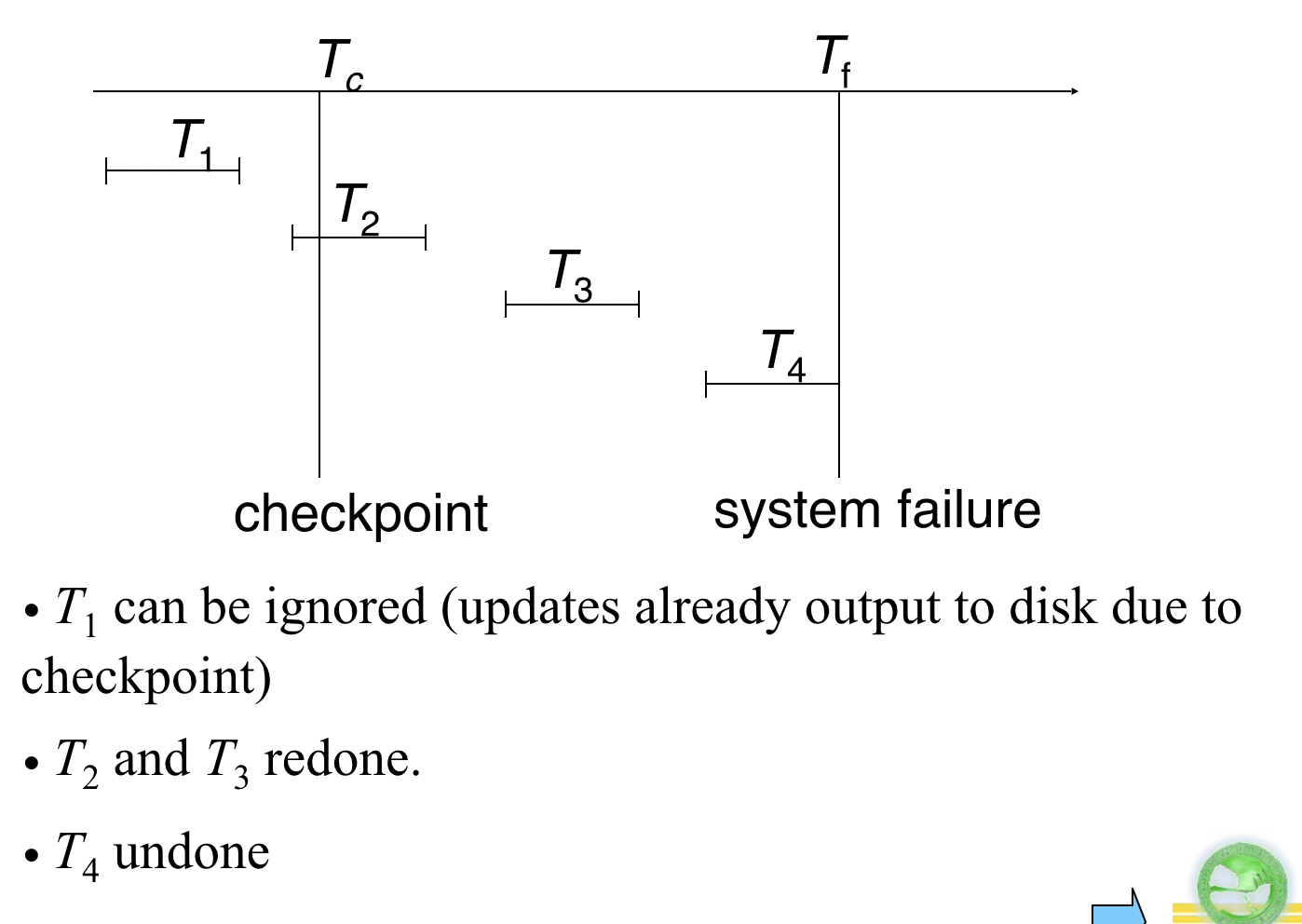
从Tc开始恢复
如果是并发事务,可以使用<checkpoint List>保存检测点时的事务列表
Undo 一定undo到start
redo 可以 redo到最近的checkpoint
如何判断一个事务需要redo还是undo?
设置一个undo-list,redo时,从最近一个checkpoint开始,将checkpoint的列表元素加入undo-list,然后向后扫描重做直到遇见committed或aborted就移出undo-list
当然,如果一个事务abort了,那自然要回滚到start的状态
然后,在undo时,从最近一个undo的事务进行回滚直到遇见start,这样子做直到undo-list为空




