
编译原理 期中复习 概述
编译原理
定义
把源程序转换成等价的目标程序的过程
程序设计语言
低级语言
- 机器语言
- 符号语言(汇编语言)
高级语言
- 过程性语言
- 专用语言
- 面向对象
编译程序
包括汇编程序和编译程序
源程序 - 高级语言/汇编语言
目标程序 - 汇编语言/机器语言
解释程序
同时处理源程序和数据
解释执行源程序,不生成目标程序
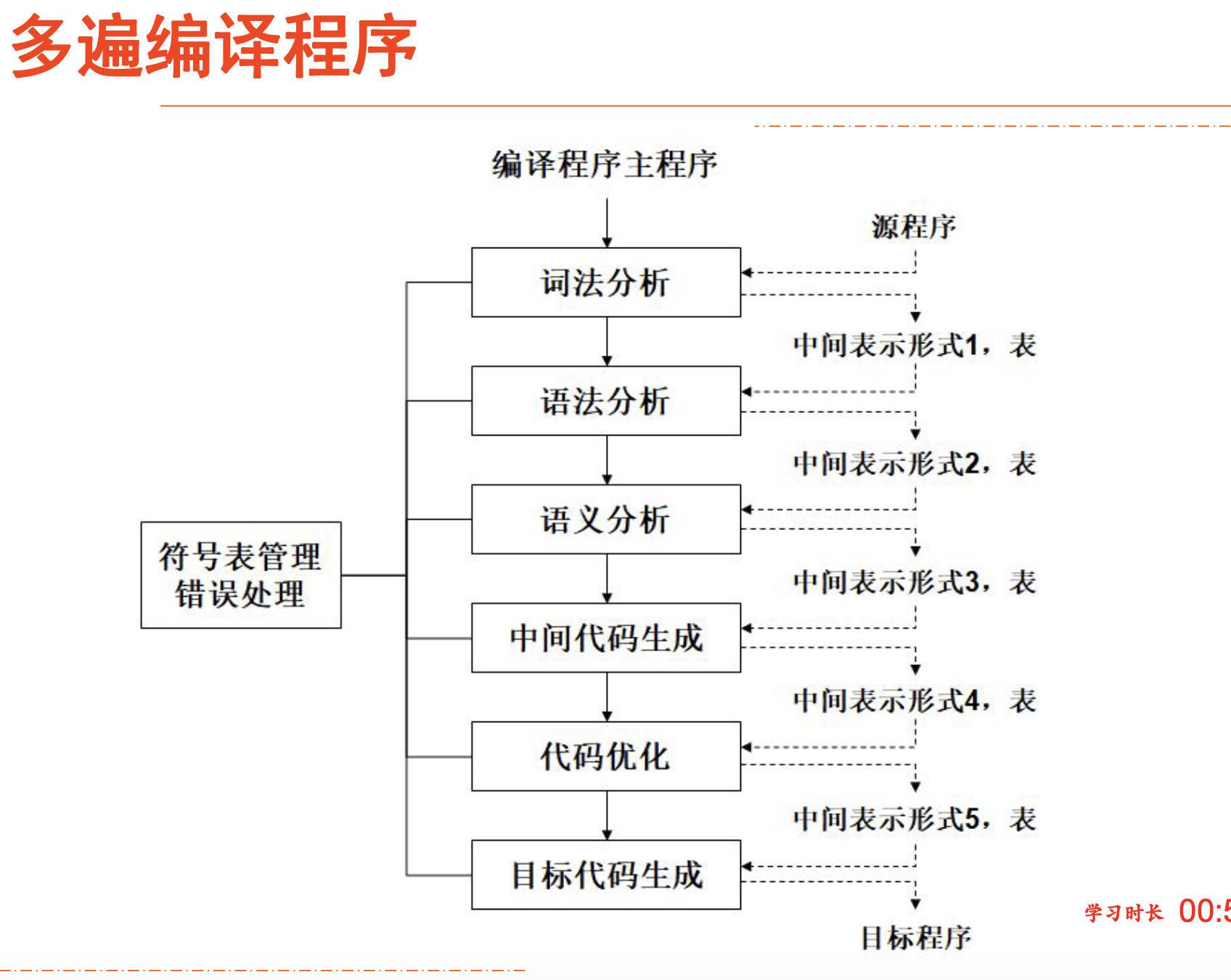
编译的阶段和任务
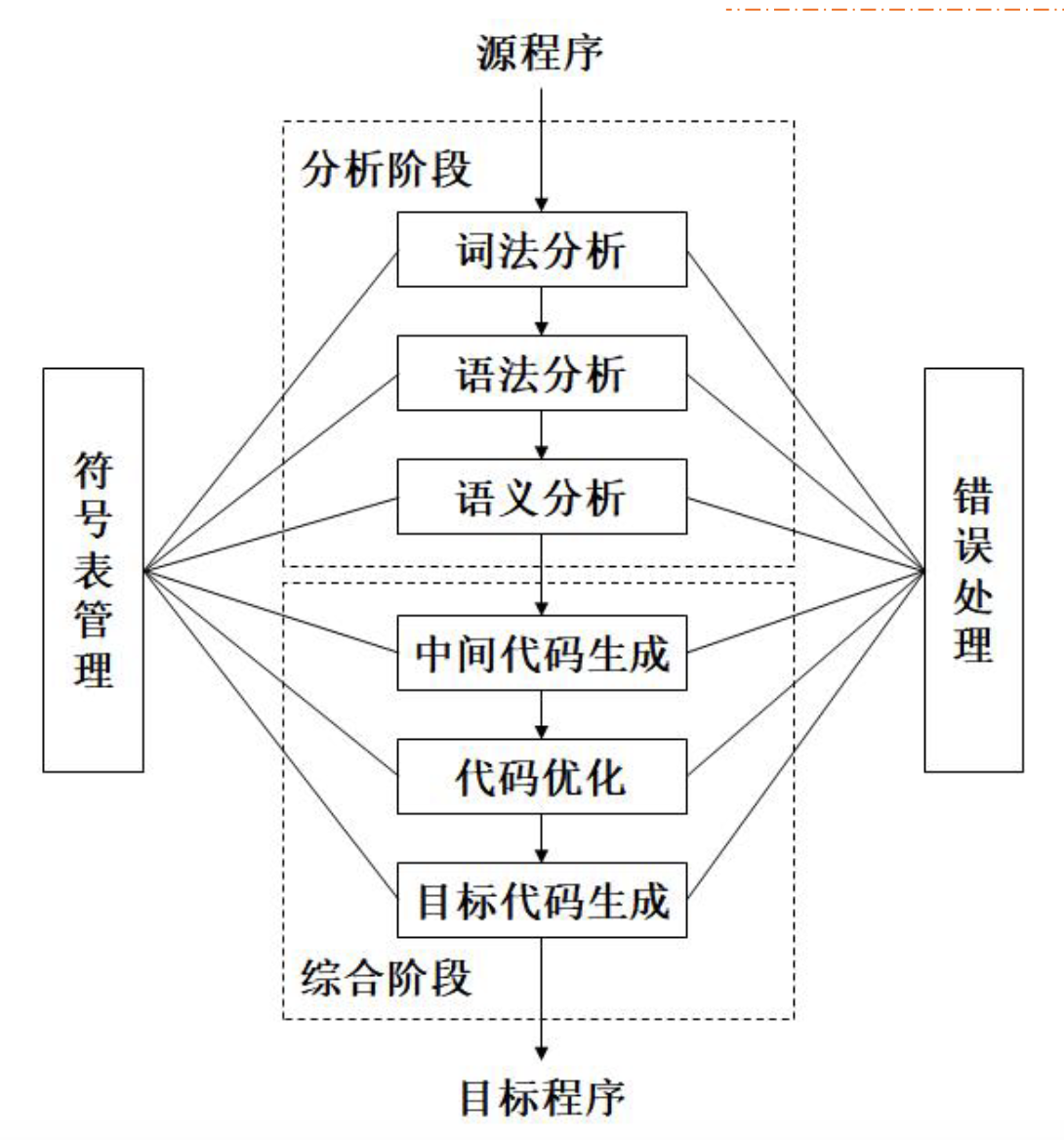
分析阶段
根据源语言的定义,分析源程序
词法分析
- 线性分析,扫描
- 负责对构成源程序的字符串进行分解和识别,将每个有独立意义的单词(lexeme)转换为记号(token),并组织为记号流
- 正规文法
- 把需要存放的单词(标识符)放到符号表中
- 工作依据:构词规则(pattern)
- 某些记号还需要属性值
语法分析
- 层次结构分析
- 工作依据:语法规则
- 上下文无关文法
- 程序的层次结构通常由递归的规则表示
- 将记号流按语言的语法结构层次地分组,形成语法短语
语义分析
-
对语法成分的意义进行检查分析
语法成分:语法分析确定的层次结构
-
收集必要信息:类型,作用域等
-
工作依据:语义规则
-
重要任务:类型检查
综合阶段
根据分析结果构造目标程序
中间代码生成
一种抽象的机器程序
- 易于产生
- 易于翻译成目标代码
- 三地址代码
代码优化
- 占用空间少
- 运行速度快
- 首先在中间代码上进行
目标代码生成
- 可重定位的机器代码
- 汇编语言代码
涉及到的两个重要问题
- 对程序中的变量要指定存储单元
- 对变量进行寄存器分配
符号表管理
- 标识符的记录、属性、变量存储分配的信息
- 语法分析阶段是不需要符号表工作的(没有符号操作)
错误诊断和处理
词法分析程序可以检测出非法字符错误
语法分析程序能够发现记号流不符合语法规则的错误
语义分析程序试图检测出具有正确的语法结构,但对所涉及的操作无意义的结构
代码生成程序可能发现目标程序区超出了允许范围的错误
由于计算机容量的限制,编译程序的处理能力受到限制而引起的错误
处理与恢复
-
判断位置和性质
-
适当的恢复
编译的其它概念
前端和后端
前端
与源语言有关而与目标机器无关的部分
- 词法分析、语法分析、符号表的建立、语义分析和中间代码生成
- 与机器无关的代码优化工作
- 相应的错误处理工作和符号表操作
后端
与目标机器有关的部分
- 目标代码的生成、与机器有关的代码优化
- 相应的错误处理和符号表操作
划分前端和后端的优点
- 便于编译程序的移植(改变后端)
- 便于编译程序的构造(改变前端)
遍(Pass)
对源程序或其中间形式从头到尾扫描一遍,并作相关的加工处理,生成新的中间形式或目标程序
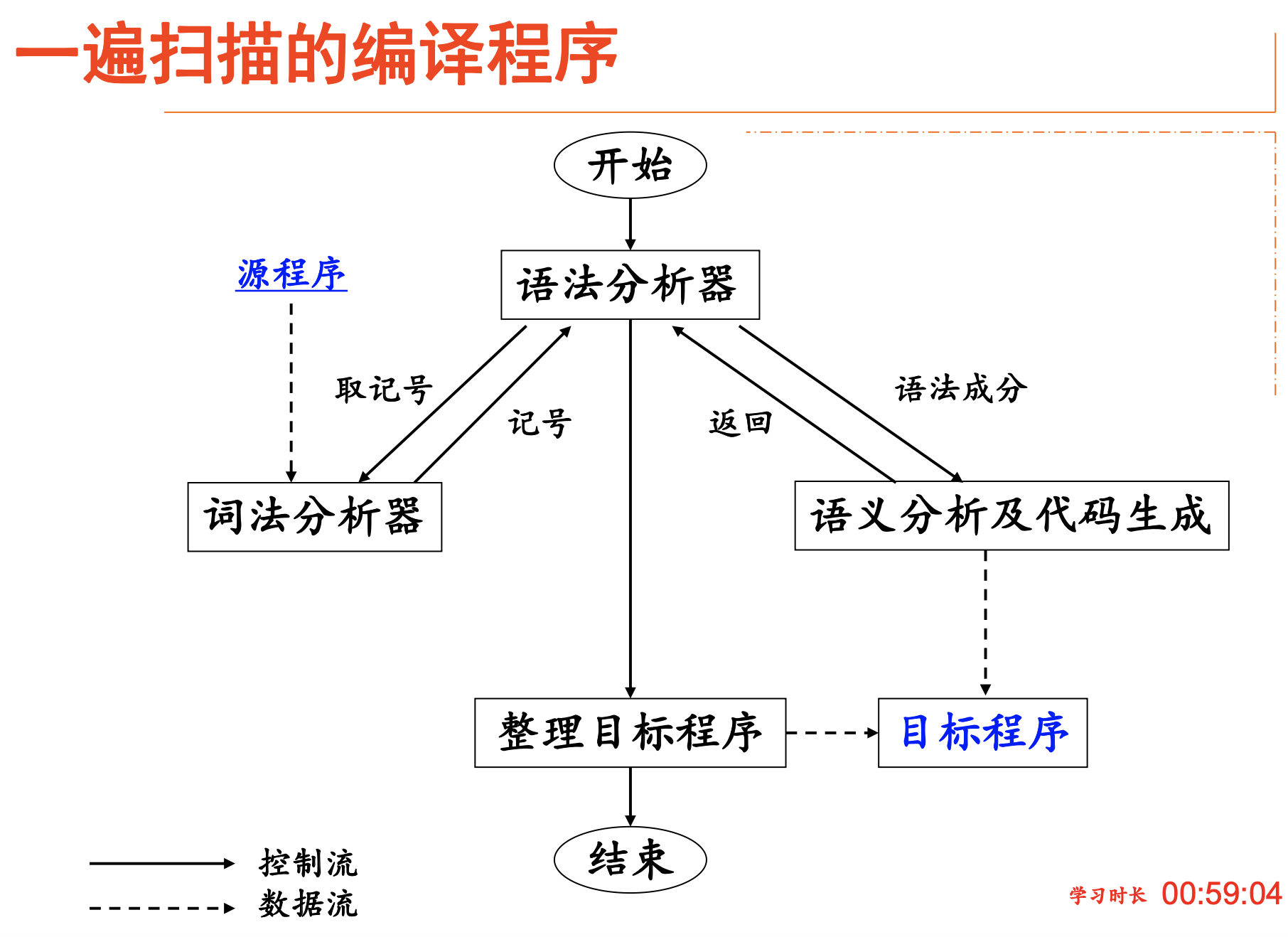
一遍扫描的编译程序没有中间代码的生成
编译程序的伙伴工具
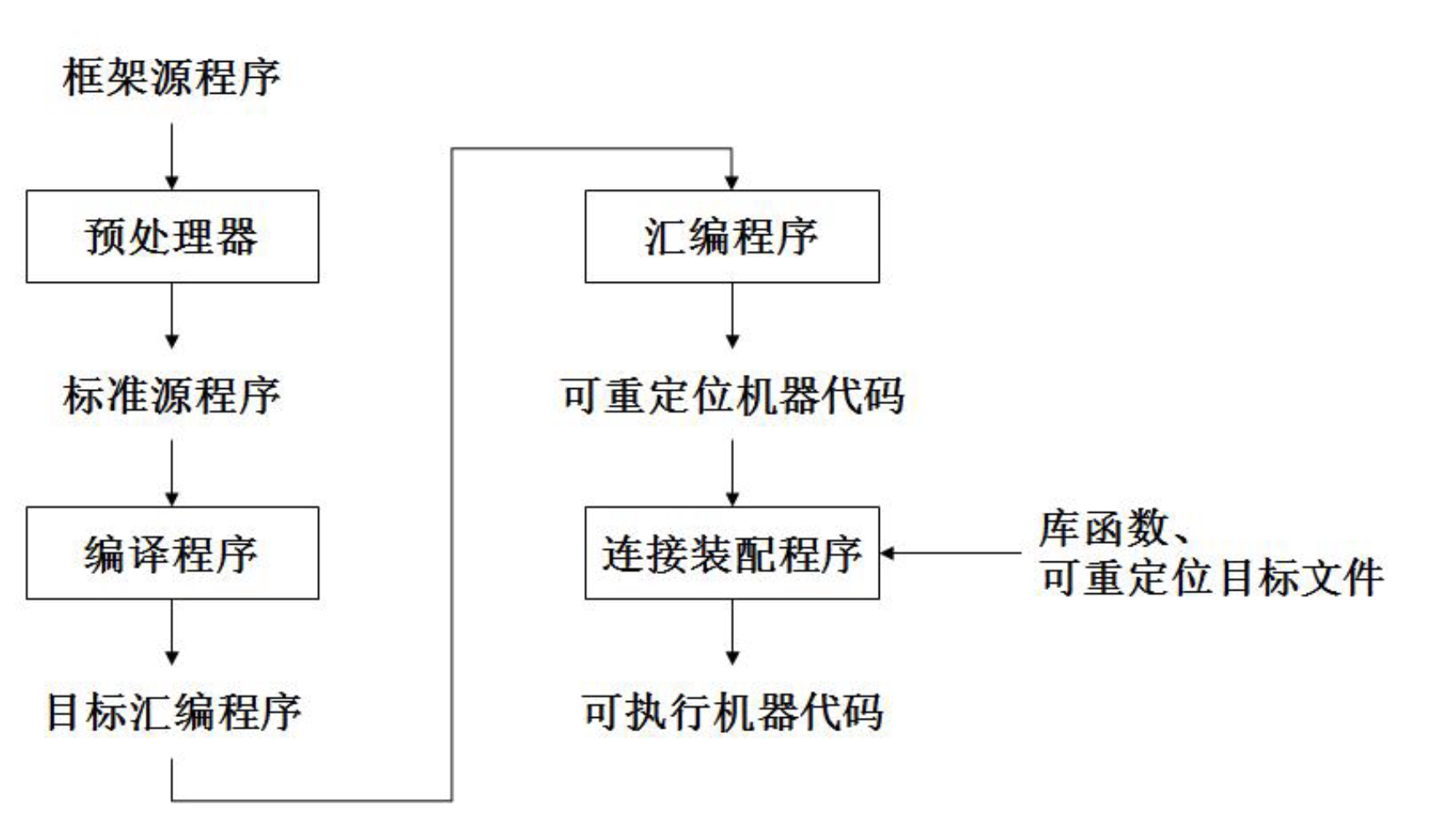
预处理器
- 宏处理器
- 文件包含
- 语言扩充
汇编程序
汇编语言用助记符表示操作码,用标识符表示存储地址
第一遍
- 找出标志存储单元的所有标识符,并将它们写入汇编符号表中
汇编符号表独立于编译程序的符号表
- 在符号表中记录该标识符所对应的存储单元地址,此地址是在首次遇到该标识符时确定的
第二遍
-
把每个用助记符表示的操作码翻译为二进制表示的机器代码
-
把用标识符表示的存储地址翻译为汇编符号表中该标识符对应的地址
-
输出:可重定位的机器代码(因为绝对机器代码的内存地址起始不一定为0x0
连接装配程序
把多个经过编译或汇编的目标模块连接装配成一个完整的可执行程序
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Ichirinko's Blog!







